Economics of 'Serverless'
Our initial goal is to try to answer questions such as when it is more appropriate to use AWS Lambda instead of AWS EC2 services, and especially, which parameters affect this comparison the most.

Introduction
In this work we examine the pricing for the serverless service from Amazon Web Services (AWS), known as AWS Lambda. We compared its pricing strategy with the AWS Elastic Compute Cloud (EC2) service, examining in detail which assumptions need to be made in order to compare both services.
We found that, far from getting a black or white answer to these questions, a variety of service specific factors can determine the best choice, and we discuss and provide specific conclusions for a number of relevant case studies.
Our approach is based on theoretical models and inspired by typical real-world services simulations that give us an insight of what variables are important to model in our planning stage when using these technologies. Indeed, those simulators, which we have open sourced, can be extremely useful during the planning stage of a software service, where it is key to determine which technologies to leverage in order to save time and money.
We will discover that having a deep knowledge on how your application works is key in order to being able to optimize its costs, and ensuring that new features do not penalize them. We will also analyze the contribution of what we called the throughput factor, that introduces a comparison method between both architectures.
Essentially, a serverless (or Function-as-a-Service, FaaS) architecture provides compute power to run your application code without needing to provision, nor manage servers. The cloud provider executes the code (called function) only when needed, and scales automatically to meet the demand.
In previous posts, we discussed the Serverless architecture, as well as the main public cloud providers that offer this architecture. Additionally, we analysed how to deploy it in-house with Fission and RedHat’s OpenShift.
Functions deployed in this service (AWS Lambda) benefit from the integration with other services from the cloud provider. However, this increases the vendor lock-in, making your app potentially unable to be deployed in other clouds. It’s worth to mention that we can only execute code using provider’s supported languages.
It is clear, just by reading the service description, that the cloud provider is focusing on different use cases for each platform: if either your workload cannot be implemented in any of the supported languages by AWS Lambda, or it is a binary from a third party, or depends heavily on the use of local storage, any cloud instance (virtual machine) offering from public cloud providers like AWS, Google, IBM or Microsoft seems the right choice. Nevertheless, there is still a lot of applications and workloads that can run in AWS Lambda that exploits its benefits; we will explore some in this work.
In this study, we focus on AWS Lambda, as it’s one of the most used serverless platforms, and supports multiple general purpose languages, like Python, Java, Go, C# and Node.js.
Most papers we have found on the issue tend to focus solely on the benefits of not having to reserve computing capacity in advance, thus saving money. In our opinion a more in-depth analysis, considering realistic workloads, would allow us to better assess the impact of this architecture on cost.
Business assumptions
In order to perform simulations and study in depth the economic impact of the serverless architecture (AWS Lambda) compared with virtual machine instances (AWS EC2), we need to make some assumptions regarding how a business might behave or be modeled:
- We assume that the application code works seamlessly both in EC2 and Lambda services. This is needed for the sake of the comparison between the two services. Most times, legacy code needs to be transformed for its direct use in a serverless platform. Monolithic apps, or software that needs to access to low-level layers of the operating system are bad candidates to run on serverless architecture without heavy code refactor. Also, the serverless cloud provider can restrict the access to some packages considered potentially dangerous, limiting the compatibility of serverless functions with code intended for regular cloud instances.
- We assume that our application is able to auto-scale the cloud instances (VMs) in service, increasing their number as the requests grow beyond the limits of requests one single instance can process.
- Notably, we don’t account for the savings in IaaS-related administration costs. For sure this could represent the tipping point when costs for both services are within the same order of magnitude. Nevertheless, it’s almost impossible to establish an assumption here, as labor costs varies widely from one country to another.
- In our simulations we have used different ratios between the amount of memory needed to process a single request using a serverless architecture versus using a cloud instance. Most often, we will use a 1:1 throughput ratio, meaning that a cloud instance can process as many requests as will fit in the total available memory, using the same amount of memory per request as a serverless function.
- Finally, we assume there’s enough expertise in our organization to code, configure and deploy serverless architectures. Although serverless architectures preclude the need for deploying a web server infrastructure, many organizations’ tech teams might not necessarily have experience deploying apps in this novel way.
Use cases covered in this work
We have identified several use cases that differ enough to be accounted separately. Most studies out there only account for the first one, at best.
One of the selling points the serverless providers often highlight is that serverless architectures preclude having to change the deployment in order to accommodate a (possibly huge) surge in workload.
How does a requests distribution over a 24-hour period affect the total cost? What about the total scale of requests? Does it make any difference using a pure local service (like a metropolitan transportation service) compared with a global one?
Digging deeper into the scalability issue, not having instances running 24/7 to reply to equally-spaced requests (like in an IoT devices case, to name one) seems to be a decent use case for serverless: it will only incur costs when a request is placed. How will it behave when the number of devices grows? Does its request frequency affect the cost comparison?
Cloud instances and Serverless pricing model. Main differences
Most cloud providers charge by the time a virtual machine is running, with a minimum upfront time of 60 seconds. Price depends on the features of the instance (such as CPU, RAM, availability and/or storage) and the commitment made upfront for using these instances. Choosing the right instance type/flavor is very application-dependant.
The function that determines the monthly cost of a Lambda instance depends on three parameters:
- The number of executions or requests (we will call it n) in that interval,
- The memory allocated by the instance (m)
- The estimated execution time (d) in milliseconds.
Thus, the total cost, Cλ , for a given amount of requests n, can be expressed mathematically as:
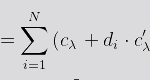
where:
- Cλ is the cost function for a given amount of requests.
- cλ is the fixed cost per request.
- di is the duration of the function (in ms)
- c’λ is the cost per second for the serverless function.
- N is the total number of requests in a given period.
On the other hand, the cost function of an EC2 instance depends, in turn, on its running time and on the max number of requests per second it can handle (rmax).
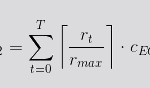
- CEC2 is the cost function for a given period T for EC2.
- rt is the number of requests to process per second.
- rmax is the maximum number of requests an instance can process per second.
- cEC2 is the cost per time unit (seconds) for a given cloud instance.
- T is the time period for the cost analysis.
Comparing serverless and cloud instances performance
We produced a theoretical model that tries to link the performance of cloud instances and serverless functions using the maximum number of reqs/sec as the linking parameter. Thus, we can express the maximum reqs/sec a cloud instance can handle in relation with the memory and time of execution on a serverless function in the following manner:
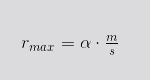
where:
- rmax is the maximum requests a cloud instance can process per time unit.
- m is the memory, in MiB, of the cloud instance.
- s is the serverless flavor memory, in MiB.
- α is a throughput ratio constant.
We introduce α in the equation to tackle the possible difference in performance between both architectures. As with other parameters already discussed in this article, this is very application-dependant, and it needs to be estimated on a case by case basis by measuring the specific impact of the following contributions:
- OS memory footprint in the cloud instances case
- Memory overhead inherent to instantiate stand-alone function to process each request (serverless case), as opposed to having one unique instance sharing its resources among multiple functions calls (cloud instances case)
- In a CPU-bound function, the execution time will be drastically affected by the AWS Lambda flavor chosen. On the other hand, an I/O bound function won’t be greatly affected by a lambda flavor with low performance CPU assigned to those low-memory flavors.
We can define throughput ratio as the quantitative relation between the memory consumed by a serverless function, versus that same function executed as regular code on a cloud instance. There are some aspects that help this parameter grow, like the smaller performance in CPU assigned to serverless functions. However, there are other features that reduce this variable, such as cloud instance OS memory footprint.
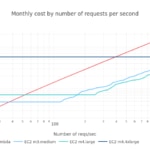
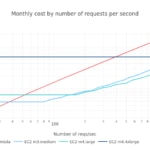
The following charts depicts the monthly costs versus the number of reqs/sec with three different throughput ratios α: 1, 5 and 10.



Technical assumptions
In order to be able to compare cloud instances pricing to serverless, we need to assume:
- Common services used by both architectures are not covered here, as they affect both in the same way. Specifically: API gateway costs, data transfer, storage and other cloud services pricing are explicitly left out of the scope of this study.
- To replicate the high availability of serverless services, our service will need a minimum of one instance running at all times, no matter its usage. That’s why none of the pre-reserved instances (spot/preemptible/reserved) are not considered in this study.
- To accommodate peaks of demand, our service will scale-out when a certain requests per second threshold is surpassed. This threshold will depend on the instance type used: the more powerful the instance is, the higher req/s it can accommodate. Thus, in this study there is no scale-up scenario where instance type is changed depending on the expected load growth.
- Our service is not suitable for offline or batch processing tasks: requests need to be processed upon arrival as quick as possible.
We have taken prices from AWS EC2 service pricing and AWS Lambda pricing for the study, as of February 2018.
Application model and parameters
In order to model an application for both architectures, we need to determine the values for the following parameters:
- Total requests in the period of study.
- Request duration, in milliseconds.
- Memory consumption for each request.
- Requests distribution over time. Although this doesn’t play a role on a serverless architecture, it does directly impact the allocated processing power over time for cloud instances.
Although the parameters are the same for both architectures, their numerical value probably won’t be the same for a given service:
- The total amount of memory needed to process a single request in a serverless architecture is higher than in a cloud instance. A serverless service needs to create the execution environment, and its memory footprint would normally be noticeably higher within this architecture.
For this reason, we cannot just divide an instance’s RAM memory between Lambda memory: this wouldn’t be fair for cloud instances.
As we have previously mentioned, we will use the throughput ratio (α) to tune this relationship between both architectures. - In contrast, we consider the same execution time in both architectures. However, it is worth mentioning that providers such as AWS assign twice as much CPU power as the serverless flavor doubles its amount of memory. This is not such an issue with Google Cloud Platform, as they have different flavors for memory and processing power combinations.
Consequently, when deciding which serverless flavor to use in AWS Lambda, the flavor (defined in terms of memory only) will affect the time the Lambda function will need to process a request, if it is CPU-intensive (as opposite to memory or I/O intensive).
Based on these premises, how do we select the serverless flavor in AWS Lambda?
- We need to allocate the minimum Lambda flavor that is able to run our code, then
- Allocate one serverless flavor which is able to consistently meet our desired service level (reqs/sec):
- We need to know if our code is CPU-bound or I/O bound:
- If it is CPU-bound: use the more powerful AWS Lambda flavor available → this will ensure a maximum service level for the same price
- If it is I/O bound, use the minimum AWS Lambda flavor available → this will ensure an acceptable service level at minimum cost.
We recommend measuring these boundaries in your code. This way you’ll be able to adapt your application to optimize pricing, and ensure that new features or changes do not penalize the costs. This is an incredibly important asset when building applications: knowing in advance the cost impact of each change.
Simulations
At BBVA-Labs, we asked ourselves how to make a cost benchmarking that covers as many cases as possible. We wanted to produce an environment which, while staying as generic as possible, would at the same time apply to the widest possible range of cases.
Bearing in mind that, we chose a simulation environment where multiple parameters can be fine-tuned to better fit a specific case. We used jupyter notebooks with Python 3.6 along with the pandas and NumPy libraries as our working environment. On top of the notebooks, we have produced a handful of Python packages that encapsulate the nitty-gritty details of cost accounting and simulation.
Alas, we will use three of the most commonly used instance types to give a good overview of how the pricing comparison evolves.
With that in mind, we propose to simulate different use cases, making different assumptions and see how they impact the model, identifying which are the most important variables when designing a service.
The source code of the notebooks and Python packages can be found in BBVA public GitHub repository.
Case 1: Uniform rate of requests per second during a whole month (aka the unrealistic case)
Scenario
This case consists in a simulation of uniformly distributed requests during a time frame of one month. We have analyzed how cost increases depending on the rate at which requests get processed by a given service.
By having a request distribution, we are able to calculate costs for using AWS EC2 instances and AWS Lambda, once we set the maximum rate (reqs/s) at which each EC2 flavor is able to process before scaling-out a new instance. Instead of using arbitrary values for each EC2 flavor, we can use the the α throughput ratio we discussed in chapter 1.4. Indeed, plots from that analysis are valid here, as we took a uniform requests distribution during a whole month to plot these graphs.
The same applies to the Lambda flavor: which memory size and execution time shall we choose?
For this specific study, we chose 128MiB, and a request time of 200ms. Different values can be used, but for the sake of simplicity we use in most cases fixed values for request duration (di) and memory. Variation in any of them will push cost curves to higher values, but the shape and slope of these curves will stay the same.
We encourage you to fork our repository and play around with the notebooks to fine-tune and meet your specific service requirements.
Most studies conclude their economic analysis here. But in real world requests don’t come in a uniform and organized way, and we asked ourselves if this could affect the economic side.
Case 2: A more humanized model
Although the previous study helps us to get a rough idea about how the scale of the demand affects the cost, the scenario where an invariable number of requests per second is maintained during the whole month is hardly believable.
Scenario
We wanted to build a more real-world related scenario, to simulate the traffic produced by a globally dispersed user base that takes into account time zones and habits. For that, we created a model based on historical traffic data (visits) from the Wikipedia site to shape the requests. Afterwards we applied a scale factor to make it grow to the desired number of total requests per month.
A random week of Wikipedia in English has the shape pictured below:
Given the historical series seems to show a strong weekly seasonality, we collapsed all Wikipedia requests during a whole year into one unique average week. Then we built a synthetic month of wikipedia requests, totalizing 100m requests in one month, and normalized it.
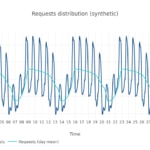
Based on this request distribution, we can now proceed to calculate the costs associated to the EC2 instance and Lambda used.
Based on the assumptions made in terms of service characteristics (memory footprint, execution time, etc), we can study how costs in a serverless infrastructure develop versus a more traditional cloud instances-based.

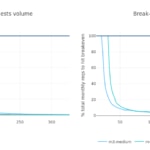
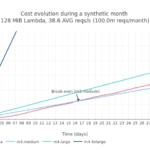
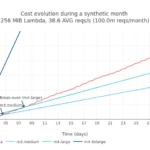
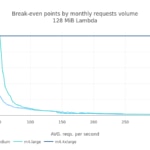
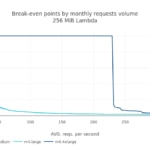
But, how do these values evolve with the total requests per month (i.e. the scale)? We analyzed when the break-even point is reached in a month versus the total amount of requests in a month. For easy reading, we use the average number of requests per second in a month:
Using this last plot we can have a visual estimation of how more expensive a Lambda architecture would be if we start receiving more requests than expected in a month.
Insights
From the previous figures, we can highlight:
- First break-even point is reached around 90 million requests per month (~35 reqs/s in average) for a 128MiB Lambda. Using a 256MiB Lambda this point is pushed to 52 million reqs/month (~20 reqs/s on average).
- Once the break-even point is reached for a given Lambda and EC2 flavor, it moves quickly, making the use of Lambda much more expensive versus a EC2 instance. This tipping point is very sensitive to the increment of a few thousand requests per month.
- Break-even point where EC2 instances start to be more cost-effective than Lambda is reached with only one instance, without needing to scale-out the number of cloud instances. Thus, the contribution of the throughput factor is irrelevant in this case.
The takeaway here is how quickly the cost benefits of having a serverless architecture degrade once our service cost goes beyond the break-even point. However, if this increase in requests is due to discrete peaks at certain moments of time, it could be acceptable.
But remember: these values are very sensitive to the maximum rate of req an instance is able to process, and to the memory and duration of the request for Lambda.
Case 3: Human users and localized traffic
Although we have analyzed how cost grows with the scale of the demand in a world-wide human-like traffic shape, we asked ourselves if this cost analysis could be affected if the traffic is more aggressively distributed during the day, like in the case of a regional app. Examples of this case could be a local council web app, metro public transportation, etc.
Scenario
We choose Dutch in this analysis as a highly localized language from wikipedia. This is what its traffic distribution looks like in one week:
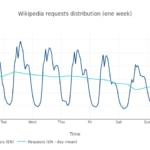
Based on that, we built a synthetic month, as we did in the previous example. Notice how it differs from the world-wide case.
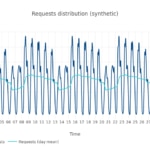
In this simulation we have a synthetic month to model a localized regional app. The scale (i.e. the total amount of requests in this month) is again 100 million (38.6 reqs/s in average). Does this hourly request distribution affect the cost, compared with the previous case? The answer is no. The break-even point is reached in the same range as previously.
Case 4: Machine to machine-like service
In this last simulation, we try to establish which factors have the biggest impact on Lambda and EC2 pricing schemes when our application’s traffic is produced by a population of devices that send requests at regular intervals. This is a particular case of an IoT-like application, such as a network of sensors.
As with previous simulations, we need to produce a request distribution, in this case it is defined by the parameters depicted below:
- It should make requests to our service at regular intervals, as defined by the device period parameter. All devices contact the server with this frequency.
- Requests from all devices during a given period are spread following a uniform distribution.
With this model, we were able to produce a request simulator that uses the device period and the number of devices as input parameters. With the request distribution over a period of time (simulation period) as output, we can easily calculate the associated costs for EC2 and Lambda.
We then obtained the cost profiles for Lambda as well as different EC2 flavors, with an increasing number of devices.
Device population and device period
More devices will produce a higher request rate over the same period. How are they related?
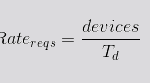
For instance, with each device making requests once every hour, that is, a device period of 3,600 seconds, the 100 reqs/s target is reached with 360,000 devices.
As in the previous simulation, a break-even point appears for each EC2 flavor that begins costing less than their Lambda counterpart. However, it’s also interesting to note that with bigger EC2 instances the chance of some of those being underutilized is also bigger, thus increasing the waste and hence the cost.
We observe that EC2 costs are slightly more expensive than the theoretical model. But the overall relationship among costs is roughly the same, using a throughput ratio of 1.
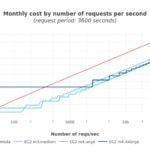
Lambda is more cost effective with a low rate of requests (<35 reqs/s for m3.medium and <50 reqs/s for m4.large). The EC2 instances become cheaper once the rate of requests increases sufficiently, with smaller EC2 instances being cheaper than the bigger ones, as bigger instances will waste more resources on average. Also note that the m3.large instance is more expensive than the m4.* ones, being obsolete already.
Applying seasonal activity
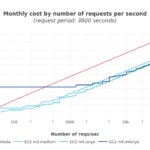
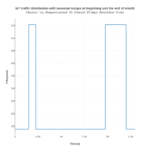
For the analysis, we arbitrarily imposed a traffic distribution with one big peak at the beginning of the month, and another peak of the same height, but wider in time, at the end of the month.
The small peak in cost in the EC2 instances correspond with traffic spikes, and can be explained by the autoscaling groups spawning more instances to absorb the excess of traffic while it lasts, and thus temporarily increasing the cost.
Conclusions
- Traffic distribution does have a considerable impact on break-even and thus, the cost. We have seen how a uniform request distribution finds its break-even point earlier in terms of average reqs/s than when traffic shape follows a more natural distribution.
- With traffic profiles where requests arrive in at periodic intervals, and a low total amount of requests, serverless architecture seems to be a great architecture in terms of cost, speed of delivery and effort. Thus, Lambda is probably the way to go if our application has sufficiently large periods of inactivity.
- Once the break-even point is reached, when EC2 is more cost-effective than Lambda, the cost difference grows rapidly, making Lambda less and less attractive in terms of cost. Thus, it is of great importance to know if the expected amount of traffic will be around the break-even point.
- Do not underestimate the savings in terms of cost of leveraging the HTTP infrastructure to the cloud provider. Also, the savings in high availability planning and deployment can push the break-even point far beyond where our theoretical studies set it, making Lambda very cost effective.
- Be aware of the CPU throttling you will get with the smaller memory flavors of Lambda. If your code is CPU-bound, choosing the smaller memory flavors might not be an option, since execution times, and thus latency, might grow beyond your requirements. On the other hand, if your code is I/O bound, the CPU throttling might not affect you significantly.
- Break-even point (if there is one, that is) strongly depends on the application itself. Without measuring the target application code, knowing the intended usage of the service, the SLA and the capabilities of the team in charge of building the application it is almost impossible to know for sure which service, Lambda or EC2, is more convenient.