Serverless con OpenShift
Este artículo es la segunda parte sobre la tecnología serverless, en donde abordamos la integración de uno de los productos más interesantes que implementan esta tecnología (Fission) en la plataforma de PaaS de RedHat, OpenShift.
Previamente a este artículo, se realizó un análisis de arquitecturas serverless o FaaS (Function as a Service), donde se introdujo esta tecnología, junto con su valor en desarrollos empresariales.

Serverless + OpenShift
Openshift, como solución PaaS de RedHat introduce mejoras de seguridad y de despliegue de aplicaciones, extendiendo Kubernetes. Openshift es el PaaS de referencia en BBVA, ayudando en el ciclo de desarrollo y despliegue continuo de aplicaciones en un entorno enterprise-ready.
Fission es una implementación de una arquitectura serverless o función como servicio (FaaS), que está diseñada para ser desplegada en Kubernetes. Una plataforma como Kubernetes es idónea para este tipo de arquitecturas FaaS, dado que permite integrar microservicios convencionales a las funciones serverless para construir aplicaciones completas que se beneficien de ambos mundos.
Fission es una implementación de una arquitectura serverless que está diseñada para ser desplegada en Kubernetes.
Apoyarse en Kubernetes y no desarrollar desde cero un producto específico de FaaS para OpenShift parece un acierto. Al fin y al cabo, la arquitectura y funcionamiento básico del software que habilita serverless sería el mismo en Kubernetes (recordemos que OpenShift se basa en Kubernetes). Por tanto, parece lógico pensar que únicamente deberá adaptarse la aplicación (Fission) para añadir las características propias de seguridad y despliegue de OpenShift. La utilización de un producto pensado para Kubernetes tiene grandes ventajas, como son:
- Amplia adopción de Fission como plataforma de referencia de FaaS sobre contenedores.
- Basado en Kubernetes, uno de los COEs líderes, con una adopción mayoritaria.
- Desarrollo activo en su repositorio de GitHub, con notable atractivo hacia la comunidad. (2000+ stars)
Arquitectura de Fission
La arquitectura de Fission está compuesta de las siguientes piezas:
- Controller. El controlador contiene APIs CRUD para funciones, triggers HTTP, entornos, y watchers de Kubernetes. Este es el componente con el que el cliente habla.
- Pool Manager. Gestiona recursos comunes (contenedores genéricos y de función). Tiene un API sencillo.
- Router. Redirige peticiones HTTP a pods de función. Si no hay un servicio corriendo para una función, solicita uno del Pool Manager, mientras mantiene abierta la petición; cuando el servicio de la función está disponible, le redirige la petición. El enrutador es stateless, y puede escalarse si es necesario, de acuerdo con la carga.
- Kubewatcher. Encargado de vigilar el API de Kubernetes, e invocar funciones asociadas con watchers, enviando el evento de watch a la función. El controlador lleva la cuenta de los watchers solicitados por el usuario y de sus funciones asociadas. Kubernetes vigila el API según dichas peticiones; cuando un evento de watch ocurre, serializa el objeto y llama a la función a través del enrutador.
- Environment container(s). Ejecutan funciones definidas por el usuario. Los contenedores de entornos son específicos de cada lenguaje. Deben contener un servidor HTTP y un cargador para funciones.
- Logger. Ayuda a redirigir bitácoras de funciones a un servicio centralizado de base de datos para la debida persistencia de dichas bitácoras.
El ciclo de vida de una función lambda en Fission
Toda arquitectura serverless soporta un número determinado lenguajes en los que podemos escribir nuestras funciones lambda. En el caso de Fission, tenemos a nuestra disposición actualmente entornos de ejecución para .NET, Go, nodeJS, PHP7 y Python3.
Los entornos de ejecución son contenedores listos para cargar y ejecutar una función lambda escrita en un determinado lenguaje. Internamente contienen un ejecutable (fetcher) que se encarga de localizar y cargar la función que deben ejecutar al ser creados.
El pool manager gestiona el ciclo de vida de los entornos de ejecución y las funciones lambda que contienen cuando se instancian.
Podemos dividir el ciclo de vida de una función lambda en la creación de la función (por parte del desarrollador), y su ejecución (por parte del usuario o aplicación cliente). En la primera parte:
- Tras escribir una función, el desarrollador la sube a Fission vía la API REST que ofrece el controller. Para facilitar la interacción con fission, disponemos del cliente fission-client, para Mac y Linux. El controller almacena en su base de datos (etcd) la función lambda y su información relacionada.
- Tras cargar la función, y también interactuando con el controller, creamos un nuevo path para poder llamar a la función mediante una URL del tipo
http://FISION_ROUTER/mi_funcion
Una vez que tenemos la función lista para ser usada, el ciclo de vida de ésta consiste en los siguientes pasos:
- Cuando se llama a la función mediante HTTP, lo que hacemos es contactar con el router, que se encarga de redirigir nuestra petición a la función adecuada. En el caso de nuestro ejemplo, una petición a
http://FISION_ROUTER/mi_funciondeberá ser atendida por la funciónhola.js. - Si la función no existe en ejecución, se instanciará un nuevo contenedor con el entorno de ejecución adecuado (nodeJS en nuestro ejemplo). A continuación, el nuevo contenedor se encargará de recuperar la función
hola.jsmediante el fetcher. - Tras unos pocos milisegundos, el contenedor estará listo para atender la petición HTTP, que le llegará a través del router.
- Una vez atendida la petición, el contenedor que contiene la función se mantiene vivo durante un tiempo determinado. Si en ese tiempo no recibe petición alguna, es destruido. A estas funciones en espera se les llama hot functions.
Profundizando un poco en la arquitectura de despliegue de Fission en Kubernetes, es importante señalar que todos los componentes, a excepción de los environment containers, se despliegan en un namespace llamado “fission”. Los environment containers que se van creando e instanciando para cada lenguaje y/o función que se crea se despliegan en un namespace diferente llamado “fission-function".
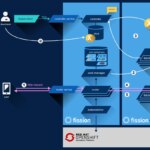
Arquitectura de Fission
Fission en OpenShift
En BBVA-Labs llevamos un tiempo trabajando con OpenShift, y hemos aportado nuestro granito de arena para poder ejecutar Fission sobre esta plataforma de PaaS.
Algunos miembros de la comunidad expresaron su interés por incorporar soporte para OpenShift, aportando algunas pistas iniciales. Al fin y al cabo, Fission funciona sobre Kubernetes, y OpenShift se apoya en esta misma tecnología.
Los principales retos en la integración Fission - OpenShift que nos hemos encontrado están relacionados con las funcionalidades mejoradas en seguridad que introduce esta solución de PaaS respecto a Kubernetes:
- Falta de permisos de un proceso para crear y/o acceder a directorios dentro del contenedor (etcd y controller)
- Permisos para que un componente (poolmanager, en el namespace fission) pueda crear nuevos pods en un namespace diferente (
fission-function)
En BBVA-Labs hemos contribuido a la comunidad de Fission una solución autocontenida para desplegar Fission sobre OpenShift. Nos alegra comunicar que nuestros cambios han sido aceptados y ya forman parte de esta plataforma FaaS.
El resultado principal es un deployment template en formato yaml. Los cambios y adiciones respecto al deployment template original de kubernetes son:
- Cambio de namespace (nomenclatura k8s) por projectRequest (OpenShist). OpenShift introduce el objeto project como una extensión de los namespaces de Kubernetes.
- Creación de un ClusterRole (
fission:poolmgr), User (fission:poolmgr) y RoleBinding (fission:poolmgr) para asignarlo al servicio poolmgr (y así poder crear pods en el namespacefission-function. - Creación de un volumen de tipo emptyDir para montarlo en
/filestoreen el pod controller y evitar problemas de permisos en OpenShift. - Configuración de etcd mediante la env
ETCD_DATA_DIRpara que escriba en un directorio donde el contenedor lanzado como usuario default si tiene permisos (/tmp)
Pasos para ejecutar Fission en OpenShift
Para probar esta solución, si no dispones de acceso a un cluster de OpenShift, recomendamos usar minishift. Al igual que minikube, se trata de un cluster autocontenido lanzado desde una máquina virtual listo para usar en cuestión de minutos.
- Igual que sucede con Kubernetes, es necesario configurar las variables de entorno
FISSION_URLyFISSION_ROUTER, apuntando al master de OpenShift:$ export FISSION_URL=http://$(minishift ip):31313 $ export FISSION_ROUTER=$(minishift ip):31314
a) Si se usa minishift o un despliegue sin load balancers, ejecutar la configuración de los servicios externos mediante NodePort. Esto expone la aplicación fission en los puertos 31313 y 31314.
$ oc login -u system:admin $ oc create -f https://raw.githubusercontent.com/fission/fission/master/fission-openshift.yaml $ oc create -f http://fission.io/fission-nodeport.yaml
b) Usando otros proveedores de cloud que admiten LoadBalancers (OpenStack, AWS, GCE/GKE):
$ oc login -u system:admin $ oc create -f http://fission.io/fission-openshift.yaml $ oc create -f http://fission.io/fission-cloud.yaml
- Después de estos pasos, ya se deberían haber desplegado todos los componentes, y tener fission listo para su uso. Para ello, hay que instalar el cliente de fission para Mac o Linux:
a) Mac:
$ curl http://fission.io/mac/fission > fission && chmod +x fission && sudo mv fission /usr/local/bin/
b) Linux:
$ curl http://fission.io/linux/fission > fission && chmod +x fission && sudo mv fission /usr/local/bin/
- Ejecutar una función de ejemplo:
1) Crear el entorno de ejecución (nodejs)
$ fission env create --name nodejs --image fission/node-env
2) Descargar y crear la función lambda:
$ curl https://raw.githubusercontent.com/fission/fission/master/examples/nodejs/hello.js > hello.js $ fission function create --name hello --env nodejs --code hello.js
3) Crear la ruta HTTP de acceso a la función:
$ fission route create --method GET --url /hello --function hello
4) ¡Invocar a la función!
$ curl http://$FISSION_ROUTER/hello Hello, world!
Conclusiones
Hemos comprobado que es posible ejecutar satisfactoriamente Fission sobre OpenShift. Esto permite disfrutar de las amplias posibilidades de una arquitectura Serverless/Lambda/FaaS en la plataforma de PaaS de referencia en BBVA (OpenShift).
Serverless nos permite desplegar sin necesidad de conocer de antemano si la aplicación recibirá algunas peticiones por hora, o miles de peticiones por segundo.
Entre otras características interesantes comentadas en el primer estudio de BBVA Labs sobre FaaS, esta arquitectura nos permite:
- Externalizar la escalabilidad de nuestros desarrollos a la infraestructura serverless, sin tener que diseñar e implementar la lógica de escalado de nuestras aplicaciones. Nos permite desplegar sin necesidad de conocer si la aplicación recibirá algunas peticiones por hora, o miles de peticiones por segundo.
- Serverless nos permite desplegar sin necesidad de conocer de antemano si la aplicación recibirá algunas peticiones por hora, o miles de peticiones por segundo.
- Reducir en consecuencia el time-to-market para poder desplegar MVPs de forma rápida y sencilla.
- Implementar ciclos de desarrollo ágiles y arquitecturas de microservicios puras.
- Usar Fission nos asegura poder desplegar nuestra aplicación en cualquier PaaS basado en Kubernetes y/o OpenShift.
No obstante, hay actualmente varios aspectos a tener en cuenta:
- La madurez de Fission es todavía temprana como para abordar un desarrollo productivo de una aplicación bancaria.
- Actualmente el versionado de funciones es manual, de forma que diferentes versiones de una función deben diferenciarse por nombre, y apuntar la ruta de la nueva versión a la nueva función. Esto podría ser una oportunidad de mejora para Fission.
- Es necesario permitir la comunicación con OpenShift/Kubernetes puro, sin capas de abstracción adicionales (y artificiales) que oculten la funcionalidad de estos PaaS.
- Los entornos de desarrollo/ejecución actualmente se limitan a cinco: Golang, Nodejs, Python, Microsoft .Net, PHP. No son pocos, pero pueden condicionar la adaptación de nuevos proyectos que no usen estos lenguajes.
- Las implementaciones de servicios stateful requieren de conexión a servicios externos (una base de datos, cola de eventos, etc). Esto no es un inconveniente per se, pero debe hacernos reflexionar acerca de si la aplicación debe construirse con funciones compuestas, que añaden un nivel de complejidad a las arquitecturas FaaS.
Te animamos a participar enviando tus comentarios a BBVA-Labs@bbva.com y, si eres de BBVA, aportando tus propuestas de publicación.