Vulnerability management in dependencies in CI / CD environments with Open Source tools
This post in 10 seconds
In this post we will address software dependency management: the security problems it implies, how to automate its management, receiving new vulnerabilities alerts in real time and how to implement a productive and satisfactory system using new Open Source tools as Deeptracy and Patton.

Estimated reading time: 20m
The importance of secure dependencies
If you are reading this post, you probably already know the importance of software dependencies in terms of security, however, let’s give it another twist:
Normally, when we talk about software dependencies, the "first layer" of dependencies always comes to mind and we forget the rest. To explain what I mean by layers, let's look at the following figure:
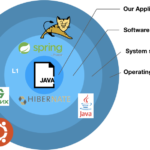
Each one of the layers is represented by a concentric circle. Each layer is labeled L1 (Layer 1), L2 (Layer 2) and L3 (Layer 3).
As we mentioned earlier, layer 1 dependencies, are the dependencies our software uses. That is, the libraries where we rely on to save time and reuse the work of others. A pretty good practice.
When a user uses our application, it has to go through 3 layers of "dependencies", which we don’t always have in mind:
- The operating system (Layer 3 - L3)
- Services on which our application is supported (Layer 2 - L2)
- Third party libraries (or own) as we have already commented (Layer 2 - L1)
Although this thought seems very obvious, we do not always remember that, like it or not, SW is surrounded by dependencies. Learning how to automate and manage your security failures can save us a lot of time and, even more importantly, headaches and disgusts.
Let us always keep in mind that the strength of our entire system depends on each and every one of its layers, and as the saying goes: a chain is as strong as its weakest link. And if any of our pieces has a vulnerability, the rest of the layers may be compromised.

Goals in dependency management
Before going any deeper, we will set some desirable goals and objectives in terms of vulnerability management of the dependencies.
These are the main goals we could consider, listed in no particular order:
- Unicity: achieve naming cohesion between different types of languages and operating systems.
- Scalability: achieving a model that can scale not only for a project, but can be adopted by any type of project.
- Unification: achieving a centralized model in which to unify and store all the information, as well as being able to manage the vulnerability cycle in the software dependencies.
- Automation: achieving to automate the entire process and be able to incorporate it into flexible work cycles.
- Proactivity: achieving a proactive system that is capable of notifying us when a new vulnerability appears in one of our projects.
- Integrability: it should be able to integrate with different environments in a simple way.
Dependency hell
When we enter the need to manage software dependencies, we encounter many problems. Until we address them, they seem simpler: lack of definition, technical decisions, etc.
We will try to list the problems that you will have to face (if you have not already done so), suggestions on how to manage it and, even better, how to automate certain parts of the process.
In order to properly monitor the vulnerabilities in dependencies, we must first be able to obtain the dependencies of our systems and services.
While this could be done by hand, no one in their right mind (and with less than 100 years) would run an inventory and monitor of all the libraries in an Excel. We need something more pragmatic, easier to use. Obviously, the simplest way to extract dependencies from our system is to ask the system itself. The reason is simple: it is the system itself that has been responsible for installing each unit. It knows where it is installed and knows how to handle it.
This process involves several problems:
- We will have to know how to ask each system.
- We will have to be able to understand the response of each of the systems we have.
- Since each system will use a different naming convention, we need to know how to understand each and every one of the conventions, or use a unified format and be able to transform any naming convention into that format.
It is not a simple problem to solve, but neither is it impossible (otherwise we would not be writing this POST, right? :D)
The problem of the naming convention
The first problem we encounter when dealing with dependency management is the following: how each dependency is named. In addition, the name is also affected by the nature of the dependency we are dealing with, in this case, a library or a service.
Dependencies of the operating system and services
Depending on the operating system we use, it is common for each provider to give a different (code-name) to the same service or library. To illustrate this, let’s use Java as an example:
OpenJDK 8 in Ubuntu
In Ubuntu Xenial, OpenJDK 8 receives the name:
openjdk-8-jre (8u171-b11-0ubuntu0.16.04.1)
OpenJDK 8 in Centos
En Centos 7, OpenJDK 8 receives the name:
java-1.8.0-openjdk-1.8.0.161-2.b14.el7
Dependencies in libraries and programming languages
As with the operating system, each programming language uses its own naming scheme for its dependencies.
Although it's not common to have the same libraries in different languages.
As we have done with the case of operating systems, let's do the same exercise:
Naming format in Java
Depending on the dependency manager used, the name of the package will be extracted differently to unify the long format, being as follows:
org.springframework:spring-webmvc:jar:5.0.6.RELEASE
Naming format in Python
Python has a much simpler naming scheme for dependencies. Just with the name of the library and the version:
In addition, if no version is specified, it is assumed that it is the latest version available at the time of installation.
The naming unification: CPE
With the cases previously described, the difficulty caused by the lack of uniqueness in the naming scheme and versioning is clear.
But, as it could not be otherwise, we are not the first to notice this problem. All software manufacturers and consumers are interested in the software being uniquely classified and identified. Having something like a single license plate would be the perfect solution for this case.
Precisely for this reason the standard CPE (Common Platform Enumeration) was born. This standard allows us to identify each software, each library and each hardware univocally. And not just the name, also the version/revision..
This is one of the not-so-well known standards but, from my point of view, one of great importance. The reason is no other than that thanks to CPE we can identify which software/version pair might contain public vulnerabilities, since the patches will come in the new versions.
If these reasons seem unimportant to you, here is one more:
When a new security vulnerability is found, the way to make it publicly available to the world (the most common) is to create a new CVE (Common Vulnerabilities and Exposures). This CVE consists of all the information of the vulnerability, in addition to an identifier that, like the CPE, is unique for each security vulnerability of a specific software. This is the way to identify it unequivocally.
The good news is that Miter (organization that manages and publishes the CVEs) associates each CVE with the software that is affected by said vulnerability and, guess what format is it published in? Effectively, in CPE format:
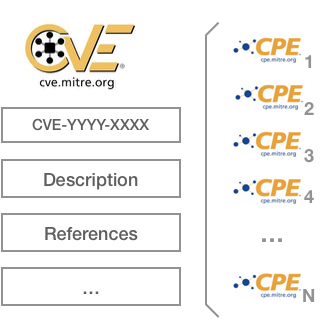
In other words:
If we manage to get the CPE identifier of a software or library, we just have to go to the CVE database and see how many security vulnerabilities are involved with it.
Problems with CPE and current software
Despite the existence of CPE as the standard naming scheme to identify any software univocally, the reality is that no software developer requests the CPE associated with its software.
Unfortunately this brings us to the initial situation, in which we have a huge chaos of names but no way to relate them to the standard CPE format.
At the time of writing this article, no solutions capable of making this translation were found. That is, given an input library name, be able to deduct your respective CPE:
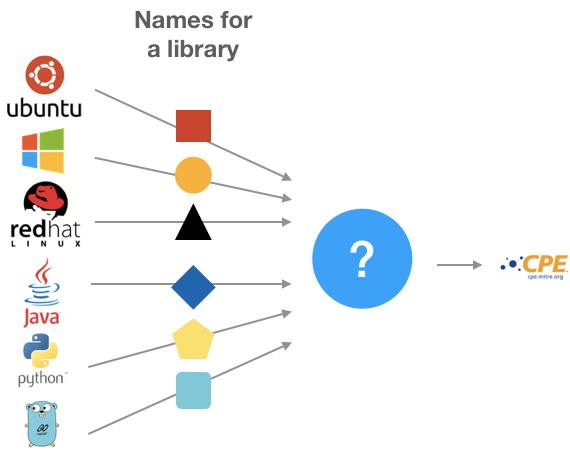
The figure above shows the possible name of a library represented with geometric shapes. Each of the forms is different, since they come from different sources and each of them uses a different name to identify the same.
This is the only impediment we have to be able to take advantage of what CPE has to offer, exposed in previous points.
But, of course... there is a plan B. Although it is true that we couldn’t find a solution readily available, we came up with our own ...
Patton: the Open Source solution for the naming problem
Patton is an Open Source initiative that we have created in BBVA-Labs to solve the problem described in the previous point.
As if that were not enough, Patton is not only able to do the translation we mentioned, it is also capable of doing the last step: once it finds the CPE, he looks for all the vulnerabilities in which a CPE is involved. In other words:
Patton is able to perform the trivial task of deducting a CPE from the name of the library and looking for its associated CVEs.
If we complete the graph of the previous point, we could summarize Patton’s operation the following way:
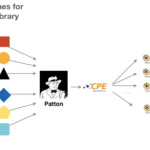
Internal operation of Patton
Without going into much implementation detail, we will briefly explain the parts Project Patton is composed of..
Patton is composed of 2 sub-projects:
- Patton server: contains all the intelligence to be able to translate a dependency name to a CPE. It exposes a standard REST API through which it can be queried.
- Patton CLI: an online command line utility that will help us carry out this process.
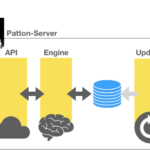
Patton Server
Patton server is composed of the following parts:
- A REST API
- A PostgreSQL database, which Patton must optimize before using it.
- The engine that provides transformation intelligence.
- An update engine to update its database with the latest published vulnerabilities.
- A notification system to alert third parties when new vulnerabilities are available
In the following diagram we can see all the parts:
Patton-CLI
The use of Patton-CLI is not mandatory but it is recommended, since it allows us to interact with the server in a very comfortable way.
We can use Patton + Patton-CLI to complement tools like Clair, which analyzes the dependencies within a Docker image.
The main advantage that Patton offers is the speed when it comes to checking the dependencies of an entire operating system (milliseconds), the lightness in computational cost resulting from its use, and the deductive mode of analysis it uses. This means that you can identify potential vulnerabilities without having a rule created for them.
Analyzing the vulnerabilities of a Docker image based on Alpine would be reduced to executing the following command:

Currently, we can use Patton-CLI to automate the analysis of operating systems based on:
- Ubuntu / Debian
- OS X
- Alpine
And the following programming languages:
- Python
- Golang
We can also analyze dependencies individually as follows:

Installation and Usage
In this short video you will find the instructions on how to install, initialize and configure Patton-Server and Patton-CLI:

The importance of automation
Most projects that already pay attention to their dependencies integrate the security analysis stages in their development cycle (or Continuous Integration/Continuous Delivery).
Although the implementation will depend a lot on the system used and how each team has designed their value stream, conceptually it could be described (at a high level) the following way:

If we expand the testing part we could have something similar to the following:

The figure above depicts some of the most usual phases in terms of testing:
- Dev testing: refers to the part of development testing (unit test, integration test, point-to-point testing ...)
- Static Application Security Testing (SAST): refers to static code security analysis.
- Dependencies: Dependency analysis is commonly seen as a test phase itself, though it can sometimes be seen as part of code analysis.
- Hacking: Although this phase should be executed right before the deployment process (with ethical hacking done by an auditor), it is good practice to do certain automatic hacking tasks whenever possible. We could also call these Abuse Stories.
Some behaviors that should exist in the previous flow:
- Blocking capacity: Each of the phases could have the ability to stop the delivery pipeline so that the software does not continue evolving to later stages. If the stage is blocked, only a privileged user should authorize or deny the step to the next phase of the pipeline.
- Failure capacity: If there is a serious enough situation the tool should stop the pipeline completely without intervention of any kind.
Depending on the type of automated tests and the amount of false positives that they yield, we must opt for one or the other. In case of doubt, being conservative, it is always better to block pending supervision.
Problems with classic workflows
If you have looked carefully at the previous security cycle, you will have noticed the following situation:
Every time a software goes to production, it will go through each one of these development and security phases, but... What happens if the software is already in production and a new vulnerability appears?
We need a system or process capable of managing this situation. That is to say:
- We need to be able to detect and list which dependencies have vulnerabilities when we are going through the continuous integration cycle.
- Once the continuous integration cycle has passed, if the software has been in production for a long time, we have no way to automatically warn of the new vulnerabilities that appear in that code, without going through the continuous integration cycle again or by installing agents that perform scans, which add management difficulties, are prone to errors and even increase our attack surface.
This is one of the most forgotten and difficult cases to solve. In order to achieve this, we need versioning and immutability in production: No manual changes in production. No SSH. All changes must go through the secure pipeline. Something usual in applications but not so much in packages and operating systems.
Automating the analysis cycle of dependencies and alerts in real time
The main problem when we try to automate dependency analysis tasks arises from the volume. If we have small projects in which we have a handful of dependencies, monitoring and managing possible vulnerabilities is relatively simple.
What would happen, however, if ...
- ... we had tens of hundreds of projects?
- ... each project had several dozen dependencies?
- ... the cycle of versions in these dependencies is very active (there are new versions every few time)?
- ... in some of our projects there are changes of some dependencies by others with the same functionality but from a different manufacturer?
The result will be:
- The impossibility of maintaining an accurate inventory of the dependencies.
- Not having a history of what dependencies we have had at any given time
- Not knowing when a vulnerability has appeared and to which dependencies it affected
- Not knowing which dependencies suffers most commonly security failures.
- Updatability index: if our dependencies are not in the latest version, this can be an indicator about how likely our system can be broken in case of updating some functionality, so in case of having to update urgently for a vulnerability we will find a difficult dilemma.
In addition to the problems described, another problem is added: ideally, the mechanism we incorporate should be easily integrated with existing C.I. as well as modern development and versioning mechanisms (such as Git).
To make matters worse, to extract the dependencies of each project it is essential to know the programming language in which it is written (if we want to automate the process). This adds an extra layer of complexity to vulnerability management.
As an additional feature, but no less important, a good security dependency management system should be able to offer us early warnings. That is, the system should be constantly monitored and when a new vulnerability appears affecting any of the included dependencies of any of our projects, it should notify the project manager and other security teams, and this should be done in the shortest period of time possible.
As a wrap up, a good dependency management system should have the following characteristics:
- Completeness: must perform a correct analysis for several languages and platforms.
- Extensibility: the solution should provide a simple way to extend its functionality.
- Lightness: it must be able to be installed and executed in the lightest possible way and without supposing an excessive load.
- Centralization: it must have a centralized repository where all the information related to each project is stored
- Traceability: should allow a traceability of the dependencies and vulnerabilities of the project over time.
- Automation: every time a new version is uploaded to the versioning repository (GIT) the dependency analysis should be launched automatically.
- Early warning: should be able to notify us of new vulnerabilities in our dependencies
Current Open Source options tested and not meeting all the requirements
At the time of writing this article, the main Open Source tool for dependency analysis is OWASP Dependency check, together with the OWASP Dependency Track, although unfortunately it only fulfills the requirement number 1: "Completeness: it must perform a correct analysis for several languages and platforms."
This tool, sponsored by OWASP, although it works well for languages such as Java or Ruby, other languages support is considered experimental.
Open Source options that meet all the requirements
Like the rest of the companies, in BBVA-Labs, we needed a tool that satisfied all the requirements detailed above (self-imposed, on the other hand). But we were not able to find anything in Open Source arena.
We found some commercial application that proposed similar approaches, but it didn’t fit our needs either. For this reason we developed the DeepTracy project.
The project was born to cover all requirements. In addition, following our philosophy of contributing to the Open Source community, you can find the tool published on Github with an Apache 2 license, as well as Patton.

Deeptracy is not just a tool. It is an extensible solution that will allow us to centralize all the dependency information related to all the projects that it analyzes.
Each time Deeptracy performs a new analysis it will also save the relationship status at the time of analysis. That is, what dependencies the project has at that moment and which of them turned out to have vulnerabilities. This feature makes Deeptracy capable of saving the entire analysis history.
Deeptracy relies on the Patton power to make the conversion between the dependency name and its corresponding CPE so we will have the power to identify each of the dependencies of our projects univocally.
Thanks to the combination of DeepTracy + Patton we can have an early warning and notification system. That is:
Patton will notify Deeptracy every time there are new public vulnerabilities in dependencies. Then, DeepTracy will check if some of the analyzed projects at some point have this dependence. If it is so, it will automatically re-launch the analysis notifying the responsible for each affected project.
Supported languages
Currently we can use DeepTracy to automate the systems analysis languages:
- Java, along with Maven and Gradle
- Python
- NodeJS
How Deeptracy works
We will support the following diagram of operation to explain how DeepTracy works:
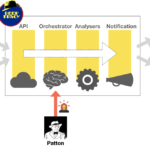
The first thing we realize is DeepTracy has four internal modules:
- API: exposes the REST interface to interact with DeepTracy.
- Orchestrator: organizes and coordinates the actions of DeepTracy.
- Analyzers: the different analyzers of each language. They will be launched depending on the type of project.
- Notification: will notify the results of the analysis.
Setting up and launching Deeptracy is very simple.
1 - DeepTracy configuration file
We created a Deeptracy configuration file and added it to our project, along with the rest of the source code.
The file must be included in the root of our project. This file is a text file stating where and in what form it will notify when the analysis or programming language of the project finishes (so DeepTracy can choose the appropriate analyzers).
2 - Register the project in project in our Git provider
Although DeepTracy can be launched manually, we can automate it through the Git hooks.
If we want that every time we do a PUSH to the Git repository of our project, DeepTracy analyze its dependencies, we will have to add a hook indicating where our DeepTracy service is located:
3 - Make a PUSH
Once the project is configured, we just have to make a PUSH to our code repository for DeepTracy start analyzing.
How do the analyzers work?
DeepTracy internally uses Docker containers to launch the analyzers. The reason is very simple:
Each analyzer of each language has different needs in terms of dependencies of the operating system and associated libraries. If we had to install all the dependencies of all our system analyzers, it would have endless unneeded development libraries.
Life cycle of the software dependency vulnerabilities
Before finalizing the post we would like to add a few strokes about the lifecycle of software dependency vulnerabilities, since their management is often not easy.
Just like the rest of critical elements, software dependencies must be monitored and followed-up.
Software dependencies involve nuances that must be properly considered for their management. They have a varied casuistry, and we may not be aware of many of these cases until we face them; for this reason we will try to provide a general vision.
Before going on, let’s clarify that this is one more approach from the many ones that exist to deal with this problem. Neither it is the only one, nor does it have to be the best. The life cycle of the software must adapt to your needs and organization, which entails considering many variables. We recommend the document proposed by NIST for vulnerability management to take ideas and see possible approaches:
https://www.us-cert.gov/sites/default/files/c3vp/crr_resources_guides/CRR_Resource_Guide-VM.pdf
To simplify our approach, we have focused on software dependencies only. That is to say: we assume that we are part of the development process of a certain piece of software, which has N library dependencies.
Below we will list the events that may occur and the questions we should ask ourselves.
1 - New vulnerability discovered
A new vulnerability in one of the libraries we use has been discovered and made public.
2 - Is the functionality used by our software?
All libraries implement plenty of functionalities. At this point we have to read the report of the published vulnerability and analyze if the functionality affected by the vulnerability is being used in our software.
In case the functionality is not being used we could opt among:
1 - Generating a report and marking the vulnerability as "non-exploitable".
2 - Trying to update our software with a patched version.
3 - Is there a security patch?
At this point we have to check if the provider has published a security patch that solves said vulnerability.
If the answer is affirmative, several situations arise:
3.1 - Cost / risk analysis
It is necessary to analyze the cost of the implementation of the security patch and the cost that this would imply in the project.
There may be situations in which it is less costly (economically speaking) to assume the economic consequences of the exploitation of the bug, than the implementation of the patch.
This situation is very common in very complex or legacy environments.
3.2 - Can it be updated?
There are certain situations in which a piece of software can not be updated without impacting the current functionality. Below we will expose some cases.
Due to compatibility; if our software is using a specific version of a library and this library exposes its functionality in a certain way, if the way in which it exposes said functionality (or API) changes in the patched version, our software will no longer be compatible with this library.
Due to lack of backward compatibility; there are cases in which security patches are only applied to the latest versions of the libraries while previous versions (with different APIs) are not updated.
Due to lack of support, if we have a previous unpatched version, despite the existence of a public patch from the manufacturer, we won’t be able to update to the fixed library and therefore, we will remain vulnerable.
In this case, we can better appreciate the need, discussed above, for the updatability index, which would be very useful as a reference value.
3.3 - Updating
In this case, we are in the best possible situation. We have updated our software with the latest version of the library, including the fixed security bug.
4 - Does the system remain in a vulnerable state?
In case our software could not be updated, for any of the reasons discussed above, we will have to check whether the fact that it has a vulnerable dependency actually makes our system vulnerable.
4.1 - Yes, our system is vulnerable
We will have to analyze and apply possible countermeasures to mitigate the risks as much as possible.
4.2 - No, our system is NOT vulnerable
This is the best of the worst situations we could have, given the circumstances. The risk is still active, but only affects specific software, not the entire system.
Whether our system is vulnerable or not, we include the active risks in our management system in order to carry out an adequate follow-up, in addition to specifying the current situation of our system.
Conclusions
The management of software dependency vulnerabilities is not a trivial problem. At first glance it may seem simple but it has many more implications than it may initially seem.
To achieve the unification of library names is not a trivial task, but we can solve it with Open Source software, like Patton.
The automation of the processes, the possibility of centralization, scalability and interaction capacities should be a key principle when we want to have a correct control of the processes and projects involved. Open Source tools, like DeepTracy, can help us in this task.
The management of the life cycle when a new vulnerability appears in some of our dependencies implies taking many decisions and measures in situations when not being able to update. Don’t forget that those decisions and measures are a critical point of our safety models.
References and links
- Deeptracy project: https://github.com/BBVA/deeptracy
- Patton-Server: https://github.com/BBVA/patton-server
- Patton-CLI: https://github.com/BBVA/patton-cli
- Deeptracy talk in OWASP Madrid (Spanish): https://www.youtube.com/watch?v=-8fhJXDuHFs