Gestión de vulnerabilidades en dependencias en entornos CI/CD con herramientas Open Source
En este post abordaremos la gestión de dependencias de software. Aquí tienes un resumen en 10 segundos:
Los problemas que ello implica, cómo ser capaces de automatizar la gestión de las mismas, recibir alertas en tiempo real ante nuevas vulnerabilidades y cómo implementar un sistema productivo y satisfactorio usando herramientas Open Source: Deeptracy y Patton.

Tiempo de lectura: 20m
Importancia de las dependencias seguras
Si estás leyendo este post, probablemente ya sabrás la importancia de las dependencias de software en lo que a seguridad se refiere, no obstante, déjame darle otra vuelta de tuerca:
Normalmente, cuando hablamos de dependencias de software, siempre nos viene a la cabeza la "primera capa" de dependencias y olvidamos el resto. Para explicar a qué me refiero con capas, observemos la siguiente figura:
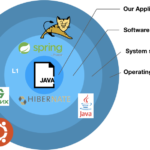
Cada una de las capas están representadas en un círculo concéntrico. Cada capa tiene la etiqueta L1 (Capa 1), L2 (Capa 2) y L3 (Capa 3).
Como comentábamos anteriormente, siempre nos vienen a la cabeza las dependencias de la capa 1, que son las dependencias de nuestro software. Es decir, las librerías en las que nos apoyamos para ahorrar tiempo y reutilizar el trabajo de otros. Una buena práctica.
Hasta que el usuario llega a nuestra aplicación, éste ha de pasar por 3 capas de "dependencias", y que no siempre recordamos:
- El sistema operativo (Capa 3 - L3)
- Servicios en los que se apoya nuestra aplicación (Capa 2 - L2)
- Librerías de terceros (o propias) como ya hemos comentado (Capa 2 - L1)
Aunque esta reflexión parece muy obvia, no siempre recordamos que, queramos o no, estamos rodeados de dependencias. Aprender a automatizar y gestionar sus fallos de seguridad puede ahorrarnos mucho tiempo y, mejor aún, quebraderos de cabeza y disgustos.
Tengamos siempre presente que la fortaleza de todo nuestro sistema depende de todas y cada una de sus capas, y tal y como dice el dicho: una cadena es tan fuerte como su eslabón más débil. Y que si alguna de nuestras piezas tiene una vulnerabilidad, el resto de las capas pueden quedar comprometidas.

Metas en la gestión de dependencias
Antes de continuar profundizando más, marcaremos unas metas y objetivos deseables en lo que a la gestión de vulnerabilidades en dependencias se refiere.
Estas son las principales metas que podríamos considerar, enumeradas sin ningún orden concreto:
- Unicidad: lograr cohesión de nombrado entre diferentes tipos de lenguajes y sistemas operativos.
- Escalabilidad: lograr un modelo que pueda escalar no solo para un proyecto, sino que pueda ser adoptado por cualquier tipo de proyecto.
- Unificación: lograr un modelo centralizado en el que poder unificar y almacenar toda la información, así como poder gestionar el ciclo de vulnerabilidades en dependencias de software.
- Automatización: lograr automatizar todo el proceso y poder incorporarlo a ciclos ágiles de trabajo.
- Proactividad: lograr un sistema proactivo, que sea capaz de notificarnos cuando una vulnerabilidad nueva aparezca en alguno de nuestros proyectos.
- Integrabilidad: debería de poder integrarse con diferentes entornos de manera sencilla.
El infierno de las dependencias
Cuando entramos en la necesidad de gestionar las dependencias de software, nos encontramos con muchos problemas. Hasta que los abordamos parecen más sencillos: indefiniciones, decisiones técnicas, etc.
Vamos a tratar de enumerar los problemas a los que te tendrás que enfrentar (si no lo has hecho ya), sugerencias sobre cómo gestionarlo y, mejor aún, cómo automatizar ciertas partes del proceso.
Para poder realizar un correcto seguimiento de las vulnerabilidades en dependencias, primero tendremos que ser capaces de obtener las dependencias del nuestros sistemas y servicios.
Si bien esto podríamos hacerlo a mano, nadie en su sano juicio (y con menos de 100 años) realizaría el inventariado y seguimiento de todas las librerías en un Excel. Necesitamos algo más pragmático, más fácil de usar. Obviamente, la forma más sencilla de extraer las dependencias de nuestro sistema, es preguntarle al propio sistema. La razón es sencilla: es el propio sistema quien se ha encargado de instalar cada dependencia. Saber dónde está instalada y saber cómo manejarla.
Aún así, este proceso implica varios problemas:
- Tendremos que saber cómo preguntar a cada sistema.
- Tendremos que ser capaces de entender la respuesta de cada uno de los sistemas que tengamos.
- Dado que cada sistema usará una convención de nombres diferente, necesitamos saber entender todas y cada una de las convenciones, o bien usar un formato unificado y ser capaces de transformar cualquier convención de nombres a ese formato.
No es un problema sencillo de resolver, pero tampoco es imposible (si no, no estaríamos escribiendo este POST, ¿verdad? :D)
El problema de la convención de nombres
El primer problema que nos encontramos cuando intentamos lidiar con la gestión de dependencias es este: cómo se nombran cada una de las dependencias. Además, y según hemos comentado más arriba, el nombrado también se ve afectado por el hecho de si la dependencia de la que hablamos es una librería o un servicio.
Dependencias del sistema operativo y servicios
Dependiendo del sistema operativo que tengamos, es muy habitual que cada proveedor le dé una codificación (code-name) diferente al mismo servicio o librería. Para ilustrarlo, pongamos el ejemplo de Java:
OpenJDK 8 en Ubuntu
En Ubuntu Xenial, OpenJDK 8 recibe el nombre:
openjdk-8-jre (8u171-b11-0ubuntu0.16.04.1)
OpenJDK 8 en Centos
En Centos 7, OpenJDK 8 recibe el nombre:
java-1.8.0-openjdk-1.8.0.161-2.b14.el7
Dependencias en librerías y lenguajes de programación
Al igual que ocurre con el sistema operativo, cada lenguaje de programación usa su propio formato para nombrar las dependencias.
Si bien es cierto que en este caso ya no tendremos (o no son los más habituales) la misma librería en un lenguaje que en otro.
Igual que hemos hecho con el caso de los sistemas operativos, hagamos el mismo ejercicio:
Formato de nombrado en Java
En función del gestor de dependencias utilizado, el nombre del paquete se extraerá de diferente forma para unificar el formato largo, quedando como sigue:
org.springframework:spring-webmvc:jar:5.0.6.RELEASE
Formato de nombrado en Python
Python tiene un formato mucho más sencillo para nombrar las dependencias. Tan solo con el nombre de la librería y la versión:
En el caso de Python, además, si no especificamos versión, se asume que es la última versión disponible en el momento de la instalación.
La unificación en el nombrado: CPE
Con los casos expuestos en las secciones anteriores queda claro la dificultad provocada por la falta de unicidad en el nombrado y versionado.
Pero, como no podía ser de otra manera, no somos a los primeros que les surge este problema. A todos los fabricantes y consumidores de software les interesa que el software pueda ser clasificado e identificado de forma unívoca. Tener algo como una matrícula única sería la solución perfecta para este caso.
Precisamente por este motivo nació el estándar CPE (Common Platform Enumeration). Este estándar nos permite identificar cada software, cada librería y cada hardware de forma unívoca. Y no solamente el nombre, sino también añadiendo la versión de los mismos.
Este es uno de los estándares no tan conocidos pero, desde mi punto de vista, más importante. El motivo no es otro que gracias a él podemos identificar qué software en qué versión/es del mismo puede contener vulnerabilidades públicas, dado que los parches vendrán en las nuevas versiones.
Si os parecen poco importantes estos motivos, aquí uno más:
Cuando se encuentra una nuevo fallo de seguridad, la forma de darlo a conocer al mundo (la más habitual) es crear un nuevo CVE (Common Vulnerabilities and Exposures). Este CVE consta de toda la información del fallo además de un identificador que, al igual que el CPE, es único para cada fallo de seguridad de un determinado software concreto. Es la forma de identificarlo de forma inequívoca.
La buena noticia es que Mitre (organismo que gestiona y publica los CVEs) asocia a cada CVE qué software está afectado por dicho fallo y, ¿adivináis en qué formato lo publica? Efectivamente, en formato CPE:
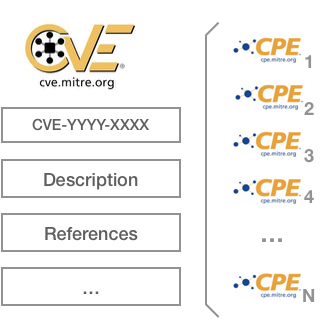
Dicho de otra manera:
Si logramos conseguir el identificador CPE de un software o librería, tan solo tendríamos que ir a la base de datos de CVE y ver en cuántos fallos de seguridad está implicado.
Problemas con CPE y software actual
A pesar de la existencia de CPE como estándar para poder nombrar cualquier software de forma unívoca, la realidad es que ningún creador o fabricante de software solicita el CPE asociado a su software.
Lamentablemente esto nos lleva a la situación inicial, en la que tenemos un tremendo caos de nombres pero no tenemos forma de lograr pasar al formato estándar CPE.
En el momento de escribir este artículo no se encontraron soluciones capaces de hacer esta traducción. Es decir, dado un nombre de librería de entrada, sea capaz de deducirnos su respectivo CPE:
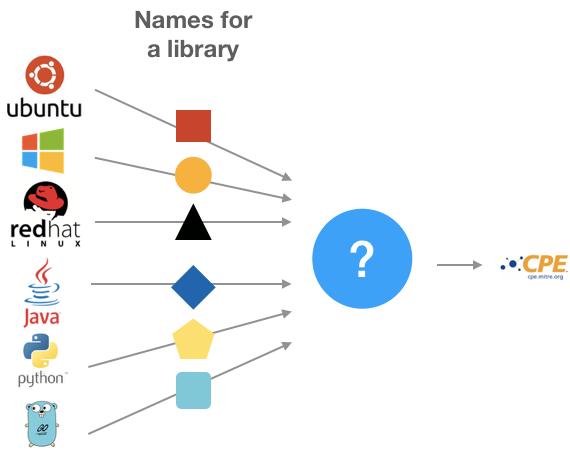
En la imagen vemos representados con formas geométricas los posibles nombres de una librería. Cada una de las formas es diferente, ya que vienen de diferentes fuentes y cada una de ellas usa un nombre diferente para nombrar lo mismo.
Este es el único impedimento que tenemos para poder aprovechar todas las ventajas de CPE, expuestas en puntos anteriores.
Pero, por supuesto… hay un plan B. Si bien es cierto que no existía una solución hasta hoy, ahora sí que la hay…
Patton: la solución Open Source para el problema de nombrado
Patton es una iniciativa Open Source que hemos creado en BBVA-Labs para resolver el problema expuesto en el punto anterior.
Por si fuera poco, Patton no solamente es capaz de hacer la traducción que comentábamos, también es capaz de hacer por si solo el último paso: una vez encuentra el CPE, busca todas las vulnerabilidades en las que está involucrado un CPE. O dicho de otro modo:
Patton es capaz de realizar la nada trivial tarea de deducir un CPE a partir del nombre de la librería y buscar sus CVEs asociados.
Si completamos el gráfico del punto anterior, podríamos resumir el funcionamiento de Patton de la siguiente manera:
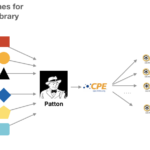
Funcionamiento interno de Patton
Sin llegar a bajar a detalle de implementación, vamos a explicar brevemente las partes del proyecto Patton.
Patton está compuesto de 2 sub-proyectos:
- Patton server: contiene toda la inteligencia para ser capaz de traducir un nombre de dependencia a un CPE. Expone un API REST estándar a través del que se puede consultar.
- Patton CLI: una utilidad en línea de comandos que nos ayudará a realizar el proceso.
Patton Server
Patton server está compuesto por las siguientes piezas:
- Un API REST
- Una base de datos PostgreSQL, que Patton debe optimizar antes de usarla.
- El engine que provee la inteligencia de transformación.
- Un motor de actualizaciones para tener actualizada su base de datos con las últimas vulnerabilidades publicadas.
- Un sistema de notificaciones para alertar a terceros cuando hay nuevas vulnerabilidades disponibles.
En el siguiente diagrama podemos ver todas las piezas:
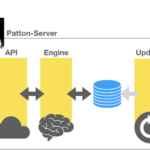
Patton-CLI
Si bien el uso de Patton-CLI no es imprescindible, sí que se recomienda, ya que nos permite interactuar con el server de una forma tremendamente cómoda.
Podemos usar Patton + Patton-CLI para complementar herramientas como Clair, que nos analiza dependencias dentro de una imagen de Docker.
La principal ventaja que nos aporta Patton es la rapidez a la hora de hacer el chequeo de las dependencias de todo un sistema operativo (milisegundos), lo liviano en costo computacional que resulta su uso, así como el modo deductivo de análisis que utiliza, lo que significa que puede identificar potenciales vulnerabilidades sin que haya sido creada un regla para ellas.
Analizar las vulnerabilidades de una imagen de Docker, basada en Alpine, se reduciría a ejecutar el siguiente comando:

Actualmente podemos usar Patton-CLI para automatizar el análisis de los sistemas operativos basados en:
- Ubuntu / Debian
- OS X
- Alpine
Y los siguientes lenguajes de programación:
- Python
- Golang
También podemos analizar dependencias de forma individual de la siguiente forma:

Instalación y uso
En este breve vídeo se pueden seguir las instrucciones sobre cómo instalar, inicializar y configurar Patton-Server y Patton-CLI:

Importancia de la automatización
El flujo normal de la mayoría de los proyectos que ya prestan atención a sus dependencias tienen parte del proceso de análisis de seguridad integrados en sus ciclos de desarrollo (o Continuous Integration).
Aunque el modo de implantación dependerá mucho del sistema usado y de cómo cada equipo haya diseñado el ciclo, conceptualmente podría describirse (a alto nivel) de forma parecida al flujo:

Si ampliamos la parte de testing podríamos tener algo parecido a lo siguiente:

En la imagen podemos observar 4 de las etapas más comunes en cuestión de testing:
- Dev testing: hace referencia a la parte de testing de desarrollo (test unitario, test de integración, pruebas punto a punto…)
- Static Application Security Testing (SAST): hace referencia al análisis de seguridad estático de código.
- Dependencias: la fase de análisis de dependencias es muy habitual que suponga una fase en sí misma, aunque algunas veces podemos verla integrada como parte de análisis de código.
- Hacking: Aunque esta fase también debería de ir al final de proceso de deploy (con hacking ético hecho por un auditor), es buena práctica hacer ciertas tareas de hacking siempre que se pueda. En esta etapa la pruebas son automáticas. También podríamos llamarlas Abuse Stories.
Comportamientos interesantes que puede que queramos que existan en el anterior flujo:
- Capacidad de bloqueo: Cada una de las fases podría tener la "potestad" para que el software no siga evolucionando a etapas posteriores, bloqueando el pipeline. Si el software está bloqueado, solo un usuario privilegiado debería autorizar o denegar el paso a la siguiente fase del pipeline.
- Capacidad de fallo: Si se da una situación lo suficientemente grave, la herramienta debería parar totalmente el pipeline sin intervención de ningún tipo.
En función del tipo de pruebas automatizadas y la cantidad de falsos positivos que estas arrojen debemos de decantarnos por una o la otra. En caso de duda, siendo conservadores, siempre es mejor bloquear en espera de supervisión.
Problemas con los flujos de trabajo clásicos
Si os habéis fijado bien en el ciclo de seguridad anterior, os habréis percatado de la siguiente situación:
Cada vez que un software va a producción pasa por todas la fases de desarrollo y seguridad. Pero: ¿qué ocurre si el software está ya en producción y aparece una nueva vulnerabilidad?
Necesitamos algún sistema o proceso que sea capaz de gestionar dicha situación. Es decir:
- Necesitamos ser capaces de detectar y listar qué dependencias tienen vulnerabilidades cuando estamos pasando por el ciclo de integración continua.
- Una vez pasado el ciclo de integración continua, si el software está en producción durante largo tiempo, no tenemos forma de advertir de manera automática las nuevas vulnerabilidades que aparezcan para las dependencias que fueron usadas en nuestros proyectos en el momento de su puesta en producción, sin volver a pasar por el ciclo de integración continua o sin instalar agentes que realicen escaneos con las dificultades de gestión, propensión a errores e incluso aumento de nuestra superficie de ataque.
Este es uno de los casos más olvidados y más difíciles de resolver. Para poder conseguirlo necesitamos versionado e inmutabilidad en producción: Nada de cambios manuales en producción. Nada de SSH. Todos los cambios deben pasar por el pipeline seguro. Algo ya habitual en aplicaciones pero no tanto en paquetes y sistemas operativos.
Automatización del ciclo del análisis de dependencias y alertas en tiempo real
El principal problema cuando tratamos de automatizar tareas como el análisis de dependencias surge del volumen. Si tenemos proyectos pequeños en los que tenemos un puñado de dependencias, el seguimiento y gestión de las posibles vulnerabilidades es algo relativamente sencillo.
Qué ocurriría, sin embargo, si...
- … tuviéramos decenas de cientos de proyectos?
- … cada proyecto tuviera varias decenas de dependencias?
- … el ciclo de versiones en dichas dependencias fuera muy vivo (hay versiones nuevas cada poco tiempo)?
- … en uno de nuestros proyectos hubiera cambios de unas dependencias por otras con la misma funcionalidad pero de un fabricante diferente?
El resultado es:
- La imposibilidad de llevar un correcto inventariado de las dependencias.
- No disponer de un histórico de qué dependencias hemos tenido en un momento dado
- No saber cuándo ha aparecido una vulnerabilidad y a qué dependencias afectaba
- Qué dependencias sufren fallos de seguridad más habitualmente.
- Índice de actualizabilidad: si nuestras dependencias no están en la última versión puede ser un indicador de que en caso de actualizar, puede romperse alguna funcionalidad de nuestro sistema, por lo que en caso de tener que actualizar de urgencia por una vulnerabilidad nos encontraremos con un difícil dilema.
Además de los problemas expuestos se suma otro problema añadido: idealmente el mecanismo que incorporamos debería de poder integrarse fácilmente con las herramientas de C.I. existentes así como los mecanismos de desarrollo y versionado modernos (como Git).
Por si fuera poco, para extraer las dependencias de cada proyecto es imprescindible conocer el lenguaje de programación en el que está escrito (si queremos automatizar el proceso). Esto añade una capa extra de complejidad a la gestión de vulnerabilidades.
Como característica adicional, pero no menos importante, un buen sistema de gestión de dependencias de seguridad debería de poder ofrecernos alertas tempranas. Es decir: el sistema debería de estar en constante vigilancia y en el momento que apareciera una nueva vulnerabilidad que afectase a alguna dependencia incluida de alguno de nuestros proyectos, debería de notificar al responsable del proyecto y a otros equipos de seguridad. Y esto debería de hacerlo en el periodo de tiempo más breve posible.
Entonces podemos concluir que un buen sistema de gestión de dependencias debería tener las siguientes características:
- Completitud: debe de realizar un correcto análisis para varios lenguajes y plataformas
- Extensibilidad: la solución debe de proporcionar una manera sencilla de extender su funcionalidad.
- Ligereza: debe de poder instalarse y ejecutarse de la forma más liviana posible y sin suponer una excesiva carga.
- Centralización: disponer de un repositorio centralizado donde se almacene todo la información relativa a cada proyecto.
- Trazabilidad: debería de permitir una trazabilidad de las dependencias y vulnerabilidades del proyecto en el tiempo.
- Automatización: cada vez que se suba una nueva versión al repositorio de versionado (GIT) el análisis de dependencias debería de lanzarse automáticamente.
- Alerta temprana: debería de ser capaz de notificarnos ante nuevas vulnerabilidades en nuestras dependencias
Opciones Open Source actuales testadas y que no cumplen todos los requisitos
En el momento de escribir este artículo la principal herramienta Open Source de análisis de dependencias es OWASP Dependency check, junto con el OWASP Dependency Track, aunque lamentablemente solo cumple el requisito número 1: "Completitud: debe de realizar un correcto análisis para varios lenguajes y plataformas."
Esta herramienta, apadrinada por OWASP, aunque funciona bien para lenguajes como Java o Ruby, el soporte del resto de lenguajes está considerado experimental.
Opciones Open Source que cumplen con todos los requisitos.
Al igual que el resto de compañías, en BBVA-Labs, necesitábamos una herramienta que satisfaciera todos los requisitos detallados más arriba (autoimpuestos, por otra parte). Pero no fuimos capaces de encontrar nada en Open Source.
Dimos con alguna aplicación comercial que proponía aproximaciones similares, pero tampoco se acababa de ajustar a nuestras necesidades. Por este motivo desarrollamos el proyecto DeepTracy.
El proyecto nació para poder cubrir todos los requisitos. Además, siguiendo nuestra filosofía de aportar a la comunidad Open Source, podéis encontrar la herramienta publicada en Github con licencia Apache 2, al igual que Patton.

Deeptracy no es solamente una herramienta. Es una solución extensible que nos permitirá tener centralizada toda la información de dependencias relativa a todos los proyectos que analice.
Cada vez que Deeptracy realiza un nuevo análisis también guardará el estado relacional en el momento de análisis. Es decir: qué dependencias tiene el proyecto en dicho momento y cuáles de ellas resultaron tener vulnerabilidades. Esta característica hace que Deeptracy sea capaz de guardar todo el histórico de análisis.
Deeptracy se apoya en el poder de Patton para hacer la conversión entre nombre de dependencia y su correspondiente CPE de manera que tendremos el poder de identificar de forma unívoca cada una de las dependencias de nuestros proyectos.
Gracias a la combinación de Deeptracy + Patton podemos tener un sistema de alerta y notificación temprana. Es decir:
Patton notificará a Deeptracy cada vez que haya nuevas vulnerabilidades públicas en dependencias. Entonces Deeptracy comprobará si alguno de los proyectos que analizó en algún momento tiene dicha dependencia. En caso afirmativo, relanzará automáticamente el análisis y notificará a los responsables de cada proyecto afectado.
Lenguajes soportados
Actualmente podemos usar DeepTracy para automatizar el análisis de los siguientes lenguajes:
- Java, con Maven y Gradle
- Python
- NodeJS
Cómo funciona Deeptracy
Vamos a apoyarnos en el siguiente diagrama de funcionamiento para explicar cómo funciona DeepTracy:
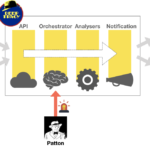
Lo primero que distinguimos es que DeepTracy consta de 4 módulos:
- API: expone la interfaz REST para interactuar con DeepTracy.
- Orchestrator: organiza y coordina las acciones de DeepTracy.
- Analysers: compuesto por los diferentes analizadores de cada lenguaje. Serán lanzados en función del tipo de proyecto.
- Notification: avisará con los resultados del análisis.
Configurar y poner en marcha Deeptracy es muy sencillo.
1 - Fichero de configuración de DeepTracy
Creamos un fichero de configuración de Deeptracy y lo añadimos a nuestro proyecto, junto al resto del código fuente.
El fichero ha de incluirse en la raíz de nuestro proyecto. Este fichero es un fichero de texto con la configuración sobre dónde y de qué forma notificará cuando finalice los análisis o lenguaje de programación del proyecto (para que DeepTracy pueda elegir los analizadores adecuados).
2 - Dar de alta el proyecto en nuestro proveedor de Git
Aunque DeepTracy puede ser lanzado de forma manual, podemos automatizarlo a través de los hooks de Git.
Si queremos que cada vez que hagamos un PUSH al repositorio de Git de nuestro proyecto, DeepTracy analice sus dependencias, tendremos que añadir un hook indicando dónde se encuentra nuestro servicio de DeepTracy:
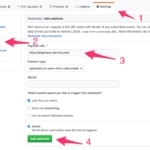
3 - Hacer un PUSH
Una vez configurado el proyecto, tan solo tenemos que hacer un PUSH a nuestro repositorio de código para que DeepTracy empiece a analizar.
¿Cómo funcionan los analizadores?
DeepTracy utiliza internamente contenedores de Docker para lanzar los analizadores. El motivo es muy simple:
Cada analizador de cada lenguaje tiene unas necesidades diferentes en cuanto a dependencias del sistema operativo y librerías asociadas. Si tuviéramos que instalar todas las dependencias de todos los analizadores de nuestro sistema, éste tendría un sin fin de librerías de desarrollo que muy probablemente no necesitemos.
Ciclo de vida de las vulnerabilidades en dependencias software
Antes de finalizar el post nos gustaría dar unas pinceladas sobre ciclo de vida de vulnerabilidades en dependencias, ya que muchas veces no es nada sencillo de gestionar.
Tal y como ocurre con el resto de elementos que hay monitorizar y realizar un seguimiento, con las dependencias de software ocurre lo mismo.
Las dependencias de software tienen matices que hay que contemplar a la hora de su gestión. Estas tienen una casuística variada, y es posible que no seamos conscientes de muchos de estos casos hasta no enfrentarnos a ellos; por este motivo vamos a tratar de aportar una visión general.
Antes de continuar, aclarar que este es un planteamiento más de los muchos que existen para afrontar este problema. Ni es el único ni tiene por qué ser el mejor. El ciclo de vida del software debe adaptarse a tus necesidades y a la organización, lo que conlleva valorar muchas variables. Para tomar ideas y ver posibles enfoques, os recomendamos el documento propuesto por el NIST para la gestión de vulnerabilidades: https://www.us-cert.gov/sites/default/files/c3vp/crr_resources_guides/CRR_Resource_Guide-VM.pdf
Para simplificar nuestro planteamiento, nos hemos centrado solamente en las dependencias de software. Es decir: asumimos que somos parte del proceso del desarrollo de un determinado software, el cual tiene N dependencias de librerías.
A continuación vamos a enumerar los eventos que pueden ocurrir y las preguntas que deberíamos de hacernos.
1 - ¿Nueva vulnerabilidad descubierta?
Una nueva vulnerabilidad en una de las librerías que usamos ha sido descubierta y hecho pública.
2 - ¿La funcionalidad es usada por nuestro software?
Todas las librerías implementan cantidad de funcionalidades. En este punto tenemos que leer el informe de la vulnerabilidad publicada y analizar si la funcionalidad afectada por la vulnerabilidad está siendo usada en nuestro software.
En caso de no estar usando la funcionalidad afectada podríamos optar por:
1 - Generar un informe y marcar la vulnerabilidad como no explotable. Posponiendo así su gestión para más adelante.
2 - Intentar actualizar nuestro software con una la versión parcheada.
3 - ¿Existe parche de seguridad?
En este punto hemos de comprobar si el proveedor ha publicado un parche de seguridad que solvente dicha vulnerabilidad.
En caso de la respuesta sea afirmativa, se nos plantean varias situaciones:
3.1 - Análisis del coste / riesgo
Hay que analizar el coste de la implantación del parche de seguridad y el costo que esto supondría en el proyecto.
Puede haber situaciones en las que es menos costoso (económicamente hablando) asumir las consecuencias económicas de la explotación del fallo, que la implantación del parche.
Esta situación es muy común en entornos muy complejos y legacy.
3.2 - ¿Se puede actualizar?
Existen ciertas situaciones en las que un software no puede ser actualizado sin romper la funcionalidad actual. A continuación expondremos algunos casos.
Por compatibilidad, si nuestro software está usando una versión concreta de una librería y dicha librería expone su funcionalidad de una determinada manera, si la forma en la que expone dicha funcionalidad (o API) cambia en la versión parcheada, nuestro software dejará de ser compatible con dicha librería.
Por falta de retrocompatibilidad, existen casos en los que los parches de seguridad se aplican a librerías solo a las últimas versiones y las versiones anteriores (con diferentes APIs) no son actualizadas.
Por falta de soporte, si contamos con una versión anterior que no ha sido parcheada, pese a la existencia de un parche público del fabricante, no podremos actualizarnos a la librería corregida y por tanto, seguiremos siendo vulnerables.
En este caso se puede apreciar mejor la necesidad, que comentamos más arriba, del índice de actualizabilidad, que nos sería muy útil como valor de referencia.
3.3 - Actualización
Si estamos en este caso, estamos en la mejor situación posible. Hemos actualizado nuestro software con la última versión de la librería con el fallo de seguridad arreglado.
4 - ¿El sistema se queda en un estado vulnerable?
En el caso de que nuestro software no haya podido ser actualizado, por cualquiera de las razones expuestas anteriormente, tendremos que comprobar si el hecho de que el mismo cuente con una dependencia vulnerable hace nuestro sistema vulnerable.
4.1 - Sí, nuestro sistema es vulnerable
Tendremos que analizar y aplicar las posibles contramedidas para mitigar los riesgos en la medida de lo posible.
4.2 - No, nuestro sistema NO es vulnerable
Esta es la mejor de las peores situaciones que podríamos tener dadas las circunstancias. El riesgo sigue activo, pero solo afecta a un software específico, no a todo el sistema.
Tanto si nuestro sistema es vulnerable, como si no, incluimos los riesgos activos en nuestro sistema de gestión para poder realizar un adecuado seguimiento, además de especificar la situación actual de nuestro sistema.
Conclusiones
La gestión de vulnerabilidades en dependencias de software no es un problema trivial. A simple vista puede parecer sencillo pero tiene muchas más implicaciones de las que puede parecer inicialmente.
Conseguir la unificación del nombrado de las librerías no es una tarea trivial, pero podemos solventarlo con software Open Source, como Patton.
La automatización de los procesos, posibilidad de centralización, escalabilidad y capacidad de interacción deberían ser una máxima cuando queremos tener un correcto control de los procesos y proyectos que los involucran. Herramientas Open Source, como DeepTracy, pueden ayudarnos en este cometido.
La gestión del ciclo vida cuando una nueva vulnerabilidad aparece en alguna de nuestras dependencias, implica adoptar muchas decisiones y medidas ante situaciones en las que no es posible actualizarse. No hay que olvidar que estas decisiones y medidas son un punto crítico en la seguridad de nuestros modelos.
Referencias y enlaces
- Proyecto Deeptracy: https://github.com/BBVA/deeptracy
- Patton-Server: https://github.com/BBVA/patton-server
- Patton-CLI: https://github.com/BBVA/patton-cli
- Presentación de Deeptracy en OWASP Madrid: https://www.youtube.com/watch?v=-8fhJXDuHFs