Serverless with OpenShift
This article is the second part about serverless, where we will cover the integration of one of the most interesting products implementing this technology (Fission) in OpenShift, RedHat’s PaaS platform.
Prior to this article, this analysis of serverless architectures or FaaS (Function as a Service) was prepared, to introduce this technology together with its value in business developments.

Serverless with OpenShift
Openshift, RedHat’s Platform-as-a-Service (PaaS) solution introduces security and application deployment improvements, extending Kubernetes. As reference PaaS in BBVA, it helps in the ongoing application development and deployment cycle in an enterprise-ready environment.
Fission is an implementation of a serverless or Function as a Service (FaaS) architecture, which is designed for its deployment on top of Kubernetes. A platform such as Kubernetes is ideal for this type of FaaS architectures, as it enables the integration of conventional microservices to the serverless functions to build full applications that benefit from both worlds.
Fission is an implementation of a serverless architecture, which is designed for its deployment on top of Kubernetes.
Relying on Kubernetes and not developing a specific FaaS product from scratch for OpenShift seems like a great idea. After all, the architecture and basic functioning of the software that enables serverless would be the same in Kubernetes (let’s not forget that Openshift is based on Kubernetes). Therefore, it seems only logical to think that it will need to adapt to the application to add OpenShift’s particular security and deployment features. The use of a product designed for Kubernetes offers huge advantages, including:
- Broad adoption of Fission as reference FaaS platform over containers
- Based on Kubernetes, one of the leading COEs, with widespread adoption
- Active development in its GitHub repository, with notable appeal for the community (2000+ stars)
Fission Architecture
Fission’s architecture consists of the following pieces:
- The controller contains CRUD APIs for Kubernetes functions, HTTP triggers, environments and watchers. This is the component with which the component talks.
- Pool Manager. Manages shared resources (generic and function containers). It has a simple API.
- Re-routes HTTP requests to function pods. If there is not a service running for a function, it requests one from Pool Manager, while the request remains open; when the service of the function is available, it re-routes the request. The router is stateless, and can be escalated if necessary, depending on the load.
- Kubewatcher. Responsible for monitoring the Kubernetes’ API and calling watcher-linked functions, forwarding the watch event to the function. The controller keeps track of the number of watchers requested by the user and their associated functions. Kubernetes monitors the API in accordance with said requests; when a watch event takes place, it serializes the object and calls the function through the router.
- Environment container(s). They execute user-defined functions. Environment containers are specific of each language. They must contain an HTTP server and a loader for functions.
- The logger helps to redirect function logs towards a centralized data base service to ensure the persistence of these logs.
The life cycle of a lambda function in Fission
Serverless architectures support a specific number of languages in which we can write our lambda functions. In the case of Fission, we currently have at our disposal execution environment for .NET, Go, nodeJS, PHP7 and Python3.
Execution environments are containers that are ready to load and execute a lambda function written in a specific language. Internally, they contain an executable (fetcher) which is responsible for locating and loading the function that they need to execute when they are created.
The pool manager handles the life cycle of the execution environments and the lambda functions they contain when they are instantiated.
We can break down a lambda function’s life cycle of a lambda into the function’s creation (by the developer) and its execution (by the user or client application). In the first part:
- After coding the function, the developer uploads it to Fission via the REST API provided by the controller. To facilitate interaction with Fission, we have the fission-client client for Mac and Linux. The controller stores the lambda function and related information in its database (etcd)
- After loading the function, and also interacting with the controller, we create a new path that will allow us to call the function by means of a URL such as
http://FISION_ROUTER/my_function
Once the function is ready for use, its life cycle consists of the following steps:
- When the function is called through HTTP, what we do is contact the router, which reroutes our requests to the right address. In our case, a request to
http://FISION_ROUTER/my_functionwill be handled by functionhello.js. - If the function does not exist in execution, a new container would be instantiated with the adequate execution environment (nodeJS is our example). Then, the new container will retrieve the
hello.jsfunction by means of the fetcher. - After a few milliseconds, the container will be ready to handle the HTTP request that it will receive through the router.
- Once the request is satisfied, the container containing the function will remain alive during a specific period of time. If, during this time no request is received, it will be destroyed. These functions in stand-by are dubbed hot functions.
Delving a bit deeper into Fission’s deployment architecture in Kubernetes, it is important to point out that all components, except environment containers, are deployed in a namespace called “fission”. The environment containers created and instantiated for each language and/or function created are deployed in a different namespace dubbed “fission-function”.
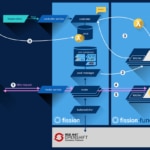
Fission Architecture
Fission in OpenShift
BBVA-Labs has been working with OpenShift for some time now and has made its humble contribution to allow executing Fission on this PaaS platform.
Some community members expressed their interest for having native support for OpenShift in Fission, offering some initial tips. After all, Fission runs on Kubernetes and OpenShift is based on this same technology.
The main challenges we have found in Fission-Openshift integration are related to the improved safety security functionalities that introduces this PaaS solution with respect to Kubernetes:
- Lack of permits of a process to create and/or access folders within the container (etcd and controller)
- Permits for a component (poolmanager, in the namespace fission) to be able to create new pods in a different namespace (
fission-function)
In BBVA-Labs we have contributed to Fission's community with a self-contained solution to deploy Fission over OpenShift. We are happy to say that our changes have been accepted and are already part of the FaaS platform.
The main result is a deployment template in yaml format. The changes and additions with respect to the original Kubernetes deployment template are:
- Change of namespace (k8s) by projectRequest (OpenShift). OpenShift introduces the project object as an extension of the Kubernetes namespaces.
- Creation of a ClusterRole (
fission:poolmgr), User (fission:poolmgr) y RoleBinding (fission:poolmgr) to assign it to the poolmgr service (and thus create pods in thefission-functionnamespace. - Creation of a volume of the emptyDir type to mount it in
/filestorein the pod controller and avoid permission issues in OpenShift. - Configuration of etcd by means of the env
ETCD_DATA_DIRto have it write in a directory where the container launched as default user does have permits (/tmp)
Steps to execute Fission in Openshift
To test this solution, if you do not have access to an OpenShift cluster, we recommend using minishift. Just as minikube, this is a self-contained cluster launched from a virtual machine ready to be used in a matter of minutes.
- Just as with Kubernetes, it requires configuring environment variables
FISSION_URLandFISSION_ROUTER, pointing at the OpenShift master:$ export FISSION_URL=http://$(minishift ip):31313 $ export FISSION_ROUTER=$(minishift ip):31314
a) If minishift – or a deployment without load balancers – execute the set-up of external services by means of This exposes the fission application in ports 31313 and 31314.
$ oc login -u system:admin $ oc create -f https://raw.githubusercontent.com/fission/fission/master/fission-openshift.yaml $ oc create -f http://fission.io/fission-nodeport.yaml
b) Using other cloud suppliers that admit LoadBalancers (OpenStack, AWS, GCE/GKE):
$ oc login -u system:admin $ oc create -f http://fission.io/fission-openshift.yaml $ oc create -f http://fission.io/fission-cloud.yaml
- After these steps, all the components should have already been deployed and fission should be ready for use. For this purpose, it is necessary to install the fission client for Mac or Linux:
a) Mac:
$ curl http://fission.io/mac/fission > fission && chmod +x fission && sudo mv fission /usr/local/bin/
b) Linux:
$ curl http://fission.io/linux/fission > fission && chmod +x fission && sudo mv fission /usr/local/bin/
- Execute an example function:
1) Create the execution environment (nodejs)
$ fission env create --name nodejs --image fission/node-env
2) Download and create the lambda function:
$ curl https://raw.githubusercontent.com/fission/fission/master/examples/nodejs/hello.js > hello.js $ fission function create --name hello --env nodejs --code hello.js
3) Create the HTTP route to access the function:
$ fission route create --method GET --url /hello --function hello
4) Call the function!
$ curl http://$FISSION_ROUTER/hello Hello, world!
Conclusions
We have verified that it is possible to satisfactorily run Fission on OpenShift. This allows enjoying the broad range of possibilities of a Serverless/Lambda/FaaS architecture in BBVA’s reference PaaS platform (OpenShift).
Serverless allows us to deploy without having to know beforehand whether the application will receive a few requests per hour or thousands of requests per second
As noted in BBVA Labs' first paper on FaaS, this architecture allows us to:
- Externalize the scalability of our developments to the serverless infrastructure without having to design and implement the escalation logic of our applications. Deploy without having to know whether the application will receive a few requests per hour or thousands of requests per second.
- Consequently, reduce the time-to-market to deploy MVPs in a simple and quick manner.
- Implement agile development cycles and pure microservice architectures.
- The use of Fission allows ensure that our application can be deployed in any PaaS based on Kubernetes and/or OpenShift.
However, there are also several issues that need to be taken into account:
- Fission is still at an early stage, too early in fact to tackle a productive development of a banking application.
- Currently, the function version assignment is still manual, in a way such that different versions of a function should be differentiated by name, pointing the route of the new version to the new function. This could be an opportunity for improvement for Fission.
- It is necessary enable communications between pure OpenShift/Kubernetes, without additional (and artificial) abstraction layers that conceal the functionality of these PaaS.
- Currently, there are only five development/execution environments: Golang, Nodejs, Python, Microsoft .Net, PHP. They are more than enough, but they can condition the adoption of new projects that do not use these languages.
- The implementations of stateful services require connecting external services (a database, event queue, etc.). This is not an drawback per se, but should make us think about whether the application should be built with compounded functions that add a complexity level to FaaS architectures.
We encourage you to send us your feedback to BBVA-Labs@bbva.com and, if you are a BBVAer, please join us sending your proposals to be published.