Seamless Networking for Container Orchestration Engines
There are a few Container Orchestration Engines available, such as Kubernetes, OpenShift, DC/OS, Nomad or Swarm, to name a few. On occasion, the optimal solution to deploy your apps requieres picking not one of those, but two or more. Each have their strenghts, and are targetted toward a specific kind of load. For instance, Kubernetes is specially prepared to deploy microservices very dynamically. However, in such a dynamic environment it is hard to handle a persistent database, task which is better handled by system such as DC/OS.

At BBVA Labs we wondered what would be the best way to make several of these COEs work together, reusing common elements and allowing each to shine in what they do best. We’ve researched how to easily and independently deploy different COEs, allowing communication between them as soon as they are deployed out-of-the-box.
Our goal is to allow multiple COEs to coexist independently, in such a fashion that they can be independently dimensioned and be scaled according to our needs.
In order to provide network connectivity, we’ve chosen to rely on standard routing protocols. Any of the software products that implement them can be replaced by others, as long as they implement the aforementioned protocols. That way we ensure interoperability, without regard to manufacturer of either hardware or software.
Introduction
When we deploy any solution to orchestrate containers (COE), each and every one of them will provide its own strategy to provide storage, security and network connectivity. When we need to extend the generic solutions provided by these COEs, most of them allow integration with third party products via somewhat standardized interfaces. For instance, in the networking realm we have Calico, Flannel and Weave, that leverage the standard CNI (Container Network Interface) plugin architecture, and for storage, GlusterFS, Ceph and Cinder implement the storage class API.
The goal of this experiment is thus to validate a common networking communications architecture between COEs that is both simple and based upon standard networking mechanisms. All while using the default deployment procedures and components of each COE. That way we allow each COE to evolve independently, as well as the lifecycles of the services deployed on them.
Furthermore, we want seamless connectivity between services deployed in different COEs, allowing the external service publishing mechanisms to be consumed from networks outside the COE where the service is deployed (public or external networks). That way, an app based on microservices could deploy each of its components within the COE that is better suited for it.
Architecture
On operation, COEs can generate new networks as often as they spawn containers, concordingly with the ephemeral nature of the cointainerized apps. In order to allow communication between services hosted on different COEs several approaches come to mind:
- Deal with each COE deployment independently, and allow the published services on each COE to be accessible frowm anywhere. This method is commonly employed by public cloud providers, such as AWS or Google, because it is easy to publish services thanks to the integration with the providers’ Load Balancer services (AWS Elastic Load Balancer or Google Cloud Load Balancer). We must ensure that our COE can be integrated with any of the aforementioned balancers, or alternatively that the COE has its own load balancer service that can be exposed (via a public IP address). In the latter case, we are also responsible of the scalability of the load balancer service.
- Use a common network solution or a Software Defined Networking (SDN) that allows to interconnect the realms of each COE. The drawback of this approach is that the SDN product must be able to integrate specifically with each COE. If we ever need to add another COE to the mix that is not supported by the SDN we chose, we’ll face a grave problem: the network solution will block its adoption.
- Leverage traditional network routing, and enable any network that can be generated within a COE to be accessible from a different COE automatically. This method should allow any two services deployed in different COEs to be able to communicate.
The first solution is very dependent on the cloud provider, and it is not always an option if we want to deploy on-premise. The second one requires that we ascertain the compatibility between the SDN product and each and every COE, and we must assume that we’ll have a perpetual vendor lock-in wit the provider of the SDN solution. The third option (traditional routing) was to our eyes a good option to be explored, as long as we were able to allow the routes to be shared and propagated with the promptness required by these container orchestration environments.
Communications within a COE
Although the process by which communications are enabled for a service or app are heavily dependent on the innards of each COE, we can actually simplify the common architecture of the COEs by using three layers:
- To each instance of the multiple and identical copies that make up a certain service (pod, worker, etc, each COE name these differently) an IP address will be assigned, which lies in a private range of that COE. Generally, the assigned network will depend on which host is the instance to be deployed.
- Each service (set of instances that perform the same job) will have an IP where its funcionality is exposed in order to be consumed by other services. The network it belongs to, must be accessible by other services and, in our case, by services deployed on other COEs.
- If a service is to be accessed from outside the COE (e.g., the frontend, or the public API of our app), a public IP address will be assigned to it and/or a load balancer is place in front of it. If the service employs HTTP(S), we will have to use an HTTP proxy that allows redirecting requests based on the URL, to the containers that should process that request. On the other hand, if the service is TCP or UDP based, the solution is to provision a load balancer that distributes traffic based on the destination port, which will be a different one for earch service. At any rate, the configuration of the proxy or load balancer must be automatic and be well integrated with the COE it serves.
Once published in this fashion, two services will communicate then through this stack. Often these communication between applications are between services that are not exposed to the outside world (such as DBs, message brokers, etc.). Thus, if we leverage the same system for allowing communication between "internal" services as for exposing public ones, we will be:
- Thwarting the compatibility with apps that cannot be exposed via a proxy or load balancer.
- Wasting precious public addressing space, or wasting resources on the load balancer or proxy. Both elements are both scarce and expensive.
Routing between COEs
As we’ve mentioned, networking in a COE is extremely dynamic: routes to access the containers of a service are created and destroyed whenever the service is resp. scaled up or down in order to tackle the demand of the moment. Luckily for us, this is taken care of by the scheduler within each COE, each within their realm. But, what about the access from the outside?
Given a service deployed in a COE, we want to be able to get access to it from another COE transparently. For that to happen, each host must now how to reach the service published on another COE. Thus, we need a way to communicate the routing information to each and every node.
Nodes are also dynamic: we can add and remove nodes to a COE when we have to. It is not as dynamic an operation as the service scaling, but we cannot assume to have a fixed topology. Each time that a new node is provisioned, a new network is created where the containers that run there will be connected to. Each time a container and/or service is registered, every node must know how to reach it.
At his point is where the routing protocols such as BGP come into play.
Enter BGP
BGP plays a critical role in the communications through the Internet. It enables the exchange of information about IP networks and the communication between what is called in BGP lore autonomous system(AS). BGP is widely used to publish networks both on the Internet and in the modern data centers, which makes it a very versatile and popular protocol.
BGP exchanges routing information between autonomous systems while also ensuring the routes to be free of loops. It is the main protocol for publishing routes employed by the big players of the Internet.
Some advantages of using an standard protocol and looking for simplicity, removing all innecessary layers:
- It is not necessary to create an overlay network (and encapsulate network traffic), and thus there’s no need to make use of tunnels or VRF tables: Simple, efficient and without hiding the actual network traffic.
- We don’t have to perform NAT: any service can reach wherever we want it to, without having to do any specific setups. We’ll be only creating the pathways so that the network traffic can flow naturally.
We have a route publishing protocol that is both dynamic and widely used; now we need a way to make it simple to integrate with the different COEs:
- We can setup and configure a BGP daemon on every host of our infrastructure, and task it with communicating the networks handled by the other nodes. BIRD is such a dameon for GNU/Linux systems, that offer a stack of routing protocols. The next step would be to configure it dynamically with a configuration management system such as Ansible, Puppet or the like, to keep the daemon on every node correctly configured all the time.
- Another option would be to make use of solutions that implement BGP and integrate with each COE. Contrary to leveraging a single SDN throughout all the COEs, this solution is matched to each COE, but stablishing a common communications framework which is BGP based, and thus allows traffic between COEs. So, if a solution turns out to be incompatible with a certain COE, it can be replaced by another one, as long as it adheres to BGP.
With independence of the solution we want to adopt, we have to think how are we going to communicate the routes of a COE to their neighbours (inter-COE). Within BGP, each node that wants to consume and/or publish network must be configured explicitly to talk to its neighbours (it boils down to having all their IP addresses). Also note that the neighbours can be dynamically created and destroyed. Two options are apparent to maintain this topology:
- Full-mesh topology: (Re)configure each node every time there is a change in the topology (such as adding/removing COEs or nodes), adding or removing the information of their neigbours.
- Use a common element to which all COEs can refer to know the topology of the others. This common element is called route-reflector, and can be any element that implements the BGP protocol, such as a traditional router, a L3 TOR(top-of-the-rack) switch, a virtualized router or a container with a BGP daemon running outside the COEs.
Calico
Calico is a communications solution that implements BGP, can be easily configured and integrates well with the COEs selected to perform this experiment: kubernetes and DC/OS. Besides, it prrovides secure network connectivity for both containers and virtual machines, and allows the assignment of dynamic IP addresses.
Calico implements BGP in order to transmit the routes of the services or containers that are deployed on each node of a COE, so that those can be accessed from the rest of the nodes of that COE. So, if we manage to get those routes published outside the COE, we’ll have a valid solution to our problem.
GoBGP
GoBGP is an open source implementation of the BGP protocol written in Golang. It can be configured in several ways, and offers a gRPC API.
In our case we’ve employed it in the laboratory as a BGP route-reflector to transmit the routes to the services between the different COEs. This approximation provides us with enought flexibility to test the model without having to deploy a full-fledged routing stack: we can configure it dynamically while we perform integrations tests.
On a production environment, it would be desirable to have a dedicated hardware router for performing this task instead.
The Experiment
Infrastructure
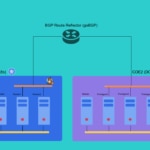
For this experiment we have several physical servers, distributed as follows:
Kubernetes 1 Controller 3 Workers DC/OS 1 Master 2 Private Agents 1 Public Agent
Additionally, we have a container running GoBGP connected to this network to act as router/route-reflector and so commuinicate the routes between COEs.
All the elements in this infrastructure live on a network with the address 172.16.18.0/24.
Basic Configuration
COEs: Kubernetes and DC/OS:
- On Kubernetes we have deployed kube-dns, kube-dashboard and heapster as per the official documentation.
- DC/OS leverages its own instance of the Marathon orchestrator to handle its internal services. We’ve installed a second Marathon instance to handle the services of the users (marathon-user), a marathon-lb (load balancer) pointing to that marathon-user, and a etcd cluster. All have been installed from the Universe repo (public repo of frameworks for DC/OS) with minimal modifications.
Deploying a second Marathon instance for the users is considered a best practice, since we are thus separating the containers run by the system from the containers run by the users, helping to keep a better resource segmentation while at the same time improving the security. Besides, it enables the communication between Calico and these containers. The marathon-user is deployed on the private DC/OS nodes along with the Calico nodes.
BGP: Route-Reflector and common configuration
When configuring BGP, the configuration relative to the neighbours must be reciprocal: both the nodes and the router must be configured. In our GoBGP setup, we’ve configured every node as a neighbour upon deployment. On each COE we configure Calico so that it distributes the location of the BGP peer.
We’ve assigned a single subnet 192.168.0.0/16 (65534 possible hosts) for the whole infrastructure, divided in two /17 segments, one for each COE:
- Subnet 192.168.0.0/17 for Kubernetes.
- Subnet 192.168.128.0/17 for DC/OS.
For simplicity, all elements of the infrastructure belong to the same Autonomous System (AS) assigned to the COEs (ASN 64511). Depending on the environment and on the degree of isolation required, we could instead assign an AS per COE, per rack or per servidor.
The configuration applied to the GoBGP daemon is shown below, having one neighbor entry for every node:
[global.config] as = 64511 router-id = "${ROUTER_IP}"
[[neighbors]] [neighbors.config] neighbor-address = "172.16.18.33" peer-as = 64511 [neighbors.route-reflector.config] route-reflector-client = true route-reflector-cluster-id = "${ROUTER_IP}"
Calico
We’ve performed a Calico setup for each of the orchestrators. Calico has been configured following the official documentation for each one. The only specific configuration on Calico for each COE was:
- The assigned subnet
- The BGP Autonomous System Number (ASN) 64511
- The information of the neighbour route reflector.
- Disabling any kind of NATting and encapsulation (IP-on-IP)
In our setup, this was the configuration employed:
-
- apiVersion: v1 kind: ipPool metadata: cidr: 192.168.0.0/17 spec: nat-outgoing: false ipip: enabled: false
- apiVersion: v1 kind: bgpPeer metadata: peerIP: 172.16.18.32 scope: global spec: asNumber: 64511
Calico’s Policy and Profile configuration
Calico is a complete communications solution, that provides also security features that complete or can be integrated with what the COE offers.
Calico uses Profiles and Policies to manage the networking access. Refer to the documentation for more details on them.
The previous configuration is not enought to enable communication between the COEs. Calico’s default policies block all traffic from outside the COE.
It is outside the scope of this study to test the security features of Calico, since we just want to test the connectivity between COEs. To perform our tests, we’ve allowed all traffic, by relaxing the Calico policies to the extreme:
- apiVersion: v1 kind: policy metadata: name: allow-all spec: types: ingress egress ingress: action: allow egress: action: allow
We’ve also applied the same rule to the Calico profiles:
- apiVersion: v1 kind: profile metadata: name: calico-open spec: egress: action: allow ingress: action: allow
Route propagation
Let’s see what happens when we have the route-reflector in place and we go on to deploy the COEs and Calico on them.
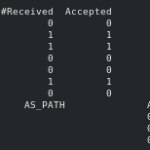
Initially, when no COE is still deployed, we can see that the route-reflector, which must have all routing info, shows that no node is connected and that no routes are shared.
Peer AS Up/Down State |#Received Accepted 172.16.18.33 64511 never Active | 0 0 172.16.18.34 64511 never Active | 0 0 172.16.18.35 64511 never Active | 0 0 172.16.18.36 64511 never Active | 0 0 172.16.18.43 64511 never Active | 0 0 172.16.18.44 64511 never Active | 0 0 172.16.18.45 64511 never Active | 0 0 Network not in table
Once we’ve deployed Kubernetes, we can see some routes being shared belonging to the initial services that use Calico networking. These services are located on the worker nodes (172.16.18.34 y 172.16.18.35). Calico has reserved a subnet of the network that it has been assigned to it on each node (192.18.55.128/26 y 192.168.119.192/26) and has communicated them to the route-reflector:
Peer AS Up/Down State |#Received Accepted
172.16.18.33 64511 00:00:30 Establ | 0 0
172.16.18.34 64511 00:00:30 Establ | 1 1
172.16.18.35 64511 00:00:30 Establ | 1 1
172.16.18.36 64511 never Active | 0 0
172.16.18.43 64511 never Active | 0 0
172.16.18.44 64511 never Active | 0 0
172.16.18.45 64511 never Active | 0 0
Network Next Hop AS_PATH Age Attrs
> 192.168.55.128/26 172.16.18.34 00:00:30 [{Origin: i} {LocalPref: 100}]
> 192.168.119.192/26 172.16.18.35 00:00:30 [{Origin: i} {LocalPref: 100}]
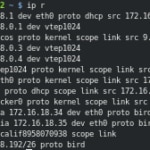
On DC/OS, none of its internal services use Calico initially. Then, to test the network we’ve deployed a service that is now running on Private Agent 2. In the same fashion that happens in Kubernetes, Calico has reserved a subnet (192.168.158.192/26) of the net it has been assigned to (192.168.128.0/17) in order to assign an IP address to this container (192.168.158.192) and has communicated it to the route-reflector.
If we access to the respective nodes and check their route table, we’ll see this:
On the Private Agent 2 of DC/OS we’ve received the routes to the services exposed by Kubernetes, propagated via route-reflector (BIRD protocol), as well as the IP address and network interface associated to our Nginx container. This would happen as well on the other DC/OS nodes:
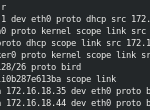
The Kubernetes Worker 1 has received the routes to the other Kubernetes node which has services deployed, as well as to the Nginx container deployed on DC/OS, using the same mechanism (BIRD protocol).
Finally, we’ve checked that we can access the Nginx container from Kubernetes via a simple WGET:
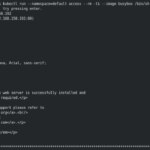
Conclusions
In this experiment we’ve been able to check the feasibility of connecting two disjoint systems each with its own networking by leveraging standard protocols and mechanisms employed on the network of networks, the Internet.
Although in this case we’ve connected directly the containers networks of Kubernetes (pod network) and DC/OS, a more interesting scenario appears, which is to extend this experiment to connect the networks of the balanced services (Service network in case of Kubernetes, and Internal Marathon-LB network in case of DC/OS).
Furthermore, a DNS solution can be employed that can group the exposed services on each COE thus simplifying between them. Many COEs already provide their on service discovery solution, the challenge being to interconnect them seamlessly.
Nevertheless, we have to keep in mind that any increase in complexity should be justified. In this case, only when more than one COE is required should we consider such a solution like the one presented here. Besides, this solution necessitates us learning to correctly deploy and scale BGP.