Delta Lake: power up your data
Transactionality in databases is fundamental for critical systems, but the historical asymmetry between reads (massive) and writes (specific, but can impact in the middle of a read operation) could be solved with a new approach. Last year Databricks released to the community a new data persistence format built on Write-Once Read-Many (HDFS, S3, Blob storage) and based on Apache Parquet.

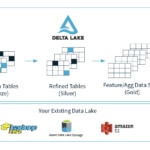
fuente: delta.io
What is Delta Lake?
Delta is an open source storage layer that provides ACID transactions through optimal concurrency control between writes and isolation of snapshots for consistent reads during writes. Delta also provides data versions to facilitate rollbacks. These are its main features:
- ACID transactions. Data concurrency control, protecting data integrity.
- Metadata scalability. Even metadata can be "big data", so using the power of Spark you can manage the scalability of petabyte tables with millions of partitions and files.
- Time travel. Data snapshots allow developers to access and revert to previous versions for auditing, rollbacks or for playing tests and experiments.
- Open format. Data is stored in Apache Parquet format, allowing Delta to take advantage of Parquet's efficient native compression and coding schemes.
- Batch and streaming. A Delta table can be either a batch table or a source or target stream.
- Schema enforcement and evolution. It provides the ability to specify your scheme and enforce it. This helps ensure the data types are correct and the required columns are present, preventing data corruption. Its flexibility allows schema modification without cumbersome DDLs.
- Audit history. Delta Lake's transaction log records the details of every change made to the data, providing a complete audit trail.
- Deletes and upserts (updates and insertions). It supports Scala / Java / Python APIs to merge, update and delete datasets. This allows you to easily comply with the GDPR and also simplifies use cases such as CDC (change data capture).
- 100% compatible with the Apache Spark API. Developers can use Delta with their existing data pipelines with minimal change as it is fully compatible with Spark.
How does Delta work?
Delta stores the schema, partitioning information, and other data properties in the same place as the data. For example, suppose we load a csv file into a Spark dataframe and persist it in Delta format in an HDFS location.

The schema and initial partitioning information can be found in file 00000.json under the _delta_log directory. The following write operations will create additional json files.

fuente: Databricks.com
In addition to the schema, the json files contain which files were added, which files were deleted and the transaction IDs. Each Delta table has a unique _delta_log directory.

fuente: Databricks.com
This is the format that one of those json files would have:
{"commitInfo":{"timestamp":1576842351569,"operation":"WRITE","operationParameters":{"mode":"Append","partitionBy":"[]"},"readVersion":0,"isBlindAppend":true}}
{"add":{"path":"part-00000.parquet","partitionValues":{},"size":1502,"modificationTime":1576842351523,"dataChange":true}}
{"add":{"path":"part-00001.parquet","partitionValues":{},"size":1502,"modificationTime":1576842350841,"dataChange":true}}
Proof of concept
To test performance we have run a small PoC in an environment with the following characteristics:
- Microsoft Azure resources
- Cluster Spark:
- 1 master/gateway with 4 cores and 14 GB RAM
- 4 workers with 8 cores and 28 GB of RAM
- Spark 2.4.4
- Delta 0.5
- Scala 2.11
- 50 GB data set of New York taxis and limousines
Here are some graphs comparing Delta vs Parquet format
write & overwrite
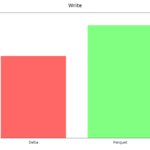
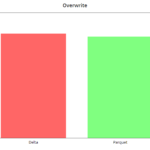
We can see the initial writing and overwriting (re-writing), in which we modified all the records for the year 2019 (about 50 million records). In the latter case, Delta has worse results if there are scheme and partition modifications.
append
We generated 50 million random data records by 2021.
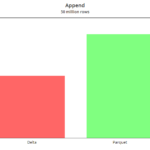
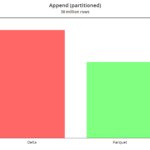
Delta improves on parquet when making an append, as long as there is no change in the schema or new partitions. In that case, the check and change of schema penalizes Delta again.
read
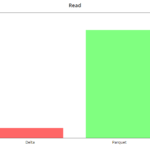
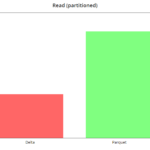
Reads are very fast in Delta, in the order of 8x in this case, we submit the query "select tripDistance from NYC where puYear = 2020" in an unpartitioned dataset (the worst case). With partitions, we see that the improvement is slighter, of the order of 2x.
In short, Delta is a very interesting format that is having a rapid adoption. Databricks is betting heavily on it, adding extra features in its runtime. Dataproc (Google Cloud) already has Delta natively in last versions and it is going to be included as another format in Apache Spark 3.
In conclusion, according to our quantitative analysis, Delta Lake can be a good approach to optimize the performance of critical transactional systems, since it proves to be able to improve reprocessing times, handle historical and versioning data, adapt to GDPR legislation and all this while controlling both concurrency and data integrity.