Delta Lake: dale potencia a tus datos
La transaccionalidad en bases de datos es fundamental para sistemas críticos, pero la histórica asimetría entre lecturas (masivas) y escrituras (puntuales, pero que pueden impactar en medio de una lectura) podría resolverse con un nuevo enfoque. El año pasado Databricks liberó a la comunidad su nuevo formato de persistencia de datos construido sobre almacenamientos del tipo 'Write-Once' 'Read-Many' (HDFS, S3, Blob storage) y basado en Apache Parquet.

fuente: delta.io
¿Qué es Delta Lake?
Es una capa de almacenamiento open source que proporciona transacciones ACID a través de un control de concurrencia óptimo entre las escrituras y el aislamiento de snapshots para lecturas consistentes durante las escrituras. Delta también proporciona versiones de datos para facilitar rollbacks. Estas son sus principales características:
- Transacciones de ACID. Control de concurrencia de los datos, protegiendo su integridad.
- Escalabilidad de los metadatos. Incluso los metadatos pueden ser 'big data', por lo que usando la potencia de Spark se puede manejar las escalabilidad de tablas de petabytes con millones de particiones y archivos.
- Time travel. Snapshots de datos que permiten a los desarrolladores acceder y revertir a versiones anteriores para auditorías, rollbacks o para reproducir pruebas y experimentos.
- Formato abierto. Los datos se almacenan en formato Apache Parquet, lo que permite a Delta aprovechar los eficientes esquemas de compresión y codificación que son nativos de Parquet.
- Batch y streaming. Una tabla Delta puede ser tanto una tabla batch como un streaming de origen o destino.
- Aplicación y evolución del esquema. Proporciona la capacidad de especificar su esquema y hacerlo cumplir. Esto ayuda a asegurar que los tipos de datos sean correctos y que las columnas requeridas estén presentes, previniendo la corrupción de datos. Su flexibilidad permite modificación de esquema sin necesidad de engorrosas DDL’s.
- Historial de cambios. El registro de transacciones de Delta Lake anota los detalles de cada cambio realizado en los datos, proporcionando auditoría completa.
- Borrados y upserts (actualizaciones e inserciones). Soporta APIs Scala / Java / Python para fusionar, actualizar y eliminar conjuntos de datos. Esto le permite cumplir fácilmente con la GDPR y también simplifica los casos de uso como CDC (change data capture)
- 100% compatible con el API de Apache Spark. Los desarrolladores pueden usar Delta con sus pipelines de datos existentes con un cambio mínimo ya que es totalmente compatible con Spark, el motor de procesamiento más usado en el planeta actualmente.
¿Cómo funciona Delta?
Almacena el esquema, la información del particionado y otras propiedades del dato en el mismo directorio que los datos. Por ejemplo, supongamos que cargamos en un dataframe de Spark un fichero csv y lo persistimos en formato Delta en una ubicación HDFS.

El esquema y la información inicial del particionado se encuentra en el fichero 00000.json bajo el directorio _delta_log. Las siguientes operaciones de escritura crearán archivos json adicionales.

fuente: Databricks.com
Además del esquema, los archivos json contienen que archivos fueron añadidos, que ficheros fueron borrados y los ID’s de transacción. A cada tabla Delta le corresponde un único directorio _delta_log.

fuente: Databricks.com
Este es el formato que tendría uno de esos ficheros json:
{"commitInfo":{"timestamp":1576842351569,"operation":"WRITE","operationParameters":{"mode":"Append","partitionBy":"[]"},"readVersion":0,"isBlindAppend":true}}
{"add":{"path":"part-00000.parquet","partitionValues":{},"size":1502,"modificationTime":1576842351523,"dataChange":true}}
{"add":{"path":"part-00001.parquet","partitionValues":{},"size":1502,"modificationTime":1576842350841,"dataChange":true}}
Prueba de concepto
Para testear su funcionamiento hemos realizado una pequeña PoC en un entorno con las siguientes características:
- Recursos de Microsoft Azure
- Cluster Spark:
- 1 maestro/gateway con 4 cores y 14 GB de RAM
- 4 workers con 8 cores y 28 GB de RAM
- Spark 2.4.4
- Delta 0.5
- Scala 2.11
- Set de datos de 50 GB de taxis y limusinas de Nueva York
Aquí os dejo unas gráficas en las que se ha comparado el formato Delta vs Parquet
write y overwrite
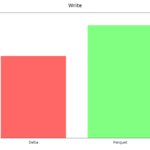
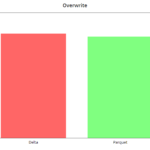
Corresponden a la escritura inicial y a la sobreescritura (reprocesado), en la que modificamos todos los registros del año 2019 (alrededor de 50 millones de registros). Este último caso Delta empeora tiempos al hacer siempre chequeo de esquema y de particionado.
append
Generamos 50 millones de registros de dato aleatorio para el año 2021.
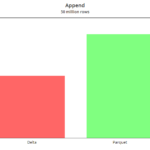
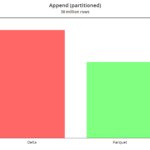
Delta mejora con respecto a parquet al hacer un append, siempre y cuando no haya modificación de esquema ni generación de nuevas particiones. En ese caso, el chequeo y cambio de esquema vuelve a penalizar a Delta como se ve en el gráfico.
read
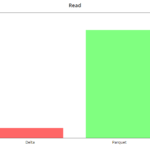
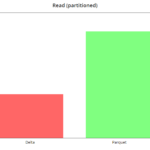
Las lecturas son muy rápidas en Delta, del orden de 8x en este caso, en el que realizamos la query "select tripDistance from NYC where puYear = 2019" en un dataset sin particionar (el peor caso). Con particiones vemos que la mejora es más leve, del orden del 2x.
En definitiva, Delta es un formato muy interesante que está teniendo una rápida adopción debido a sus múltiples bondades. Databricks está apostando fuerte por él, añadiéndole funcionalidades extra en su runtime. Dataproc (Google Cloud) ya posee Delta de manera nativa en sus últimas versiones y va a ser incluido como un formato más en Apache Spark 3.
Concluyendo, según nuestro análisis cuantitativo, Delta Lake puede ser un buen enfoque de cara a optimizar el rendimiento de sistemas críticos transaccionales, dado que demuestra ser capaz de mejorar tiempos de reprocesado, manejar un histórico y versionado de los datos, adaptarse a la legislación GDPR y todo ello controlando tanto la concurrencia y la integridad del dato.