Accelerating the training of deep neural networks with MxNet on AWS P3 instances
Deep Learning techniques are providing amazing results on several Machine Learning fields, but training a complex deep neural network on a large dataset can take a significant amount of time. Therefore accelerate training of Deep Learning models is really crucial, but also challenging.

At BEEVA Labs we performed some internal benchmarks testing several data-parallel implementations of well-known image classification models: on Tensorflow, Keras+Tensorflow and MxNet. Our first experiments were focused on typical MNIST and CIFAR10 datasets, comparing different GPU-enabled cloud infrastructures, and we shared our first conclusions on factors that affect performance and efficiency of training.
Curiously, one of the main lessons we learned was that we should stop benchmarking deep neural networks on typical hello-world datasets as MNIST or CIFAR10. As we described in our first conclusions with more detail, images on these datasets are too small and computation required for processing each sample is minimal. Thus it’s difficult to adequately saturate the GPU utilization with regular batch sizes to exploit the possibilities of modern GPUs.
Accordingly, in the next experiments we tried a more practical approach, focused on fine-tuning pretrained models with new data. The goal of these experiments is also to measure the cost-efficiency of data-parallel scaling on multiple GPUs with MxNet on Amazon Web Services (AWS) instances. To complement our previous research presented on the refered post, and to extend the analysis of some aspects that affect scalability.
Fine tuning of pretrained models on AWS P2 instances with MxNet
ImageNet dataset has more than 1 million images divided into 1000 classes, and the complete Imagenet dataset-Imagenet11k- with 10000 categories is 10x larger. Usually we don't need to train a model with all the ImageNet dataset, as research groups on Facebook or Google do, and it's not usual to have such a big dataset. In our case it's much more practical to fine-tune a pretrained model. Moreover to train the full dataset has a computational cost much higher. For instance, a single experiment to train a state-of-the-art ResNet model on ImageNet for 100 epochs could cost hundreds of dollars on the cloud. And it could last for days unless a highly scalable implementation and infrastructure is available. Otherwise, as we will see, using a model pretrained on Imagenet and fine-tuning to a smaller dataset can be done in minutes. With good levels of accuracy and infrastructure costs lower than 3 dollars.
Fine-tuning a model with new data is related to the concept of transfer learning. Instead of training the model from scratch we replace the last fully-connected layer with a new one that outputs the desired number of classes. It's the better alternative to avoid overfitting if we don't have enough data, and it's also a cost effective way to take benefits from complex models pretrained on huge datasets. Though it's not a panacea that you can apply in all cases.
So we followed the MxNet example to use a model pretrained on ImageNet11K with a ResNet architecture, and fine-tune this model to the smaller Caltech256 dataset.
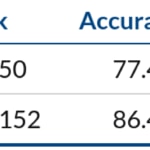
According to MxNet documentation, state of the art results on Caltech256 dataset get an accuracy of 86.4% with Resnet-152.
Fine-tuning a ResNet152 model pretrained on Imagenet11K with MxNet. Throughput when scaling from 1 GPU K80 on a p2.x to 8 K80 on a p2.8x
We experimented with the following scenario:
- instances: {p2.x, p2.8x}
- model: ResNet152
- GPUs: {1, 8}
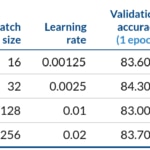
- batch-size: {16, 32} x #GPUs
- learning rate= {0.00125, 0.0025} x #GPUs
- default configuration: "optimizer=sgd"…
To run the experiments, on a Deep Learning AMI Ubuntu Linux - 2.4_Oct2017 (ami-37bb714d), with MxNet v0.11.0, and CUDA-8:
$ cd src/mxnet/example/image-classification $ ./data/caltech256.sh $ python fine-tune.py --pretrained-model imagenet11k-resnet-152 \ --gpus 0 --data-train caltech256-train.rec \ --data-val caltech256-val.rec --batch-size 16 \ --num-classes 256 --num-examples 15240 \ --num-epochs 1 --lr 0.00125
As an example, with the p2.8x, to use 8 GPUs with a batch size of 32 x 8, and a learning rate of 0.02:
$ python fine-tune.py --pretrained-model imagenet1k-resnet-50 \ --gpus 0,1,2,3,4,5,6,7 --data-train caltech256-train.rec \ --data-val caltech256-val.rec --batch-size 256 \ --num-classes 256 --num-examples 15240 \ --num-epochs 1 --lr 0.02
After completing 1 epoch we got validation accuracy between 83.0% and 84.3%, so accuracy degradation between the best and worst case was under 1%. And we got 96% efficiency scaling to 8 gpus. As we could expect an ideal speedup of 8x in relation to 1 gpu, and actual speedup was 7.7x.
First of all, we had to check that we didn't have a bottleneck reading the data. For this purpose MxNet image classification examples provide the option "test-io". So we confirmed the throughput of data feeding was high enough. Even with 3 threads of decoding, it was above 1500 images/s.

Fine-tuning a ResNet152 model pretrained on Imagenet11K with MxNet. Throughput when scaling from 1 GPU K80 on a p2.x to 8 K80 on a p2.8x
After 6 epochs on 8 K80 on a p2.8x we achieved state-of-art validation accuracy: 86.5%. In approximately 10 minutes. Adding other 10 minutes required to set-up the environment, the infrastructure costs less than $3 with on-demand prices.
We also changed the model to ResNet50 pretrained on Imagenet1k. In this case, after 6 epochs we get a validation accuracy of 75.5%. And we got 94% efficiency scaling to 8 gpus. In general, models with less computation complexity in relation to the number of parameters to be shared can achieve lower efficiency rates.
Fine-tuning a ResNet152 model pretrained on Imagenet11K with MxNet. Throughput when scaling from 1 GPU K80 on a p2.x to 8 K80 on a p2.8x
From Kepler to Volta
All the previous experiments were based on P2 instances with NVIDIA Tesla K80 GPUs. As NVIDIA says, the world's most popular GPU. Tesla K80 is the most common GPU in the cloud. In fact, at December 2017, is the only GPU available all three of Amazon Web Services, Microsoft Azure and Google Cloud Platform.
However Kepler architecture was introduced in 2012. Tesla K80 was launched 3 years ago. And after Kepler they came successively Maxwell, Pascal, and… Volta!
Volta architecture is available on AWS via the new EC2 P3 instances since the end of October 2017. P3 series incorporates 1 to 8 Tesla V100. Main characteristics of these instances are described in the following figure.
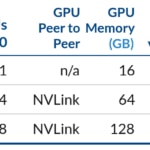
AWS EC2 p3.2xlarge, p3.8xlarge and p3.16xlarge instances. - https://aws.amazon.com/es/ec2/instance-types/p3/
On-demand prices are between $3/h for p3.2xlarge and $24/h for p3.16xlarge. This is approximately 3x more expensive than analogous P2 instances with the same number of GPUs.
Moreover, AWS p3 instances, as NVIDIA DGX supercomputers, allow to use optimized containers from NVIDIA GPU Cloud. As a curiosity, current price of DGX-1 with 8 V100 is $149 000.
Since December 4th NVIDIA GPU Cloud containers are supported also by TITAN GPUs. Thus we can now use these containers from our PCs. And also with powerful but relatively common and cheap GPUs as GeForce® GTX Titan X Pascal.
Fine tuning of pretrained models on AWS P3 instances
We repeated our fine-tuning experiments in these new P3 instances, to compare with the previous results on P2. For this purpose we used the NVIDIA Volta Deep Learning AMI, with the optimized MxNet container from NVIDIA GPU Cloud (nvcr.io mxnet:17.10) running on CUDA-9.
- Scenario:
- model: ResNet152
- instances: {p3.2x, p3.8x}
- GPUs: {1, 4}
- batch-size: {16, 32} x #GPUs
- learning rate = {0.00125, 0.0025} x #GPUs
We fine-tuned a pretrained ResNet152 model with batch sizes of 16 and 32 images. And instances p3.2x and p3.8x.
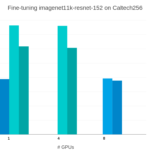
Fine-tuning a ResNet152 model pretrained on Imagenet11K with MxNet. Throughput when scaling from 1 GPU V100 on a p3.2x to 4 V100 on a p3.8x
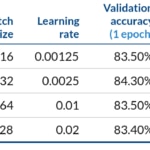
Fine-tuning a ResNet152 model pretrained on Imagenet11K with MxNet. Throughput when scaling from 1 GPU V100 on a p3.2x to 4 V100 on a p3.8x
In terms of on-demand prices, not only the throughput was much higher, but it's also more cost efficient.
However, the scarcity of EC2 P3 instances at the moment causes a high volatility in the spot market. Specially for p3.16xlarge instances, where you can find prices even much higher than on demand. Moreover "capacity-not-available" error messages are currently usual when requesting for p3.8x spot instances at market prices.
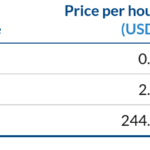
EC2 P3 prices on spot market. On November 2017 - AWS
Optimizations from NVIDIA GPU Cloud, NCCL and OpenBLAS
Finally we tried to isolate the benefits from NVIDIA GPU Cloud MxNet container. And also the benefits of support to NVIDIA Collective Communication Library (NCCL). For this purpose we used Deep Learning Base AMI (Ubuntu) Version 2.0 on a p3.8xlarge. This AMI includes an installation of NCCL version.
So we repeated the fine-tuning experiment, with ResNet152, using MxNet open-source releases, instead of NVIDIA containerized version. First tests were directly with python mxnet-cu90 package. With versions 0.12.0 and 1.0.0
For 4 gpus, throughput rates were 15% slower for batch-size of 16x4. But less than 1% slower for batch-size of 32x4.
Moreover MxNet 1.0.0 was recently released with experimental support to NCCL. According to MxNet claims, with kvstore='nccl'"users can train a model 20% faster on multi-GPU systems" in some cases. And it should be "significantly faster than kvstore='device' when batch size is small".
In order to test this feature we had to compile with USE_NCCL=1. Furthermore, we had to configure the following steps to use the NCCL installed version. For this purpose execute this as root or administrator if necessary:
# mkdir /usr/local/nccl
# cp /lib/nccl/cuda-9/ /usr/local/nccl/lib/ -r
# mkdir /usr/local/nccl/include
# cp /usr/include/nccl.h /usr/local/nccl/include/
# incubator-mxnet
# make -j $(nproc)
USE_OPENCV=1
USE_BLAS=openblas
USE_CUDA=1
USE_CUDA_PATH=/usr/local/cuda
USE_CUDNN=1
USE_NCCL=1
USE_NCCL_PATH=/usr/local/nccl/
# export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/nccl/lib
Surprisingly or not, for this particular scenario we were not able to get any throughput improvement by enabling NCCL. Otherwise, with "kvstore nccl", throughputs were even between 3% and 4% slower than default "kvstore device" configuration.
However, by compiling MxNet from source code with USE_BLAS=openblas we achieved approximately the same performance we got with NVIDIA GPU Cloud container.
Conclusions
Summarizing our main conclusions, from scientific, engineering, infrastructure and business points of view:
- Batch sizes and learning rates. Large batch sizes reduce overhead in communication, increasing throughput. But they also degrade convergence. Recently Facebook AI Research has proposed a method to circumvent this issue in practice by progressively scaling the learning rate.
- Data pipeline. Data feed and hard disk can be the main bottleneck. Moreover to efficiently scale it's important that implementation overlaps computation and communications.
- Architecture. In our experiments last V100 architecture on P3 instances was much faster and even more cost effective that previous Kepler on P2 instances.
- Pricing. Spot instances in AWS is a useful way to get cost effective instances. Unfortunately P3 instances are still scarce and their spot prices have high volatility.
- MxNet framework cares about efficiency: In our MxNet experiments, similar efficiency levels where achieved even without the optimizations from NVIDIA that we tested: NCCL library and NGC container. Moreover MxNet image classification examples have an easy way to check for bottlenecks on data feeding. And default configurations work out-of-the-box quite well.