Software Supply Chain Management
After the incidents of the previous months (SolarWinds, Codecov,...) it is becoming more evident that it is necessary to have a strong inventory and control over the components with which we build our software, as well as to strengthen the process used to build it.

That list of components of our software is what we called SBOM (Software Bill of Materials), and it’s a key component for managing our supply chain, which is one of multiple entrypoints of vulnerabilities for our software, as the aforementioned incidents have shown.
As a good proof of the importance of securing our SBOM is the Executive Order issued by the US president Joe Biden in May, which will impose new and strict standards for every software that is to be acquired by the United States federal administration, including some measures aimed to improve the security in the Software Supply Chain.
Introduction
In this article we are going to make a proposal, without delving into implementation details, of a process for managing our software dependencies, in order to reduce as much as possible the probability of getting in trouble derived from existing vulnerabilities in those dependencies and that will allow us to quickly respond upon the threats that may appear in the future. In no case will we be able to remove those issues completely, but it will help us to make informed decisions and act quickly when the threats arise.
What do we need?
We are going to enumerate a list of elements and configurations that we will need in order to be able to implement the process.
- The software components, or artifacts, (whether they be main products or their dependencies) are usually stored in the so called artifact repositories. To have the maximum guarantees on the origin and integrity of said artifacts, we must have a private artifact repository, in which all the components used to build our software will be stored.
- This repository should support assigning metadata to the artifacts, that metadata will be used to fill in the inventory and to make the enforcement during deployment. In case this functionality is not supported an external service can be developed and integrated so all this information can be stored and recovered outside of the repository. It is also required to have support for event generation when new artifacts are included, deleted or their data is modified.
- The CI/CD tooling (because nobody is deploying software in production by hand nowadays , isn’t it?) used to build and deploy our software will only have access to the private repository and, in addition, will be the only party with write permissions so nobody can add or replace software in a fraudulent way. This will allow us to ensure that only verified artifacts are used. CI/CD tooling will use the artifacts metadata to verify them and to make decisions about whether or not the built software and its dependencies can be deployed in production.
- Our developers should use our private repository instead of the public ones, although this is not mandatory. The process that we are going to describe will not impose limitations in the access to external dependencies in development time, so it will not incur in delays when, for example, evaluating different alternatives; however, using the private repository from the first stages of development will accelerate all the software dependencies verification process, because all of them will be known from the very beginning.
Description of the Process
Before proceeding with the explanation of the process I would like to state its main objectives:
- The process wants to have inventoried, verified and protected all those elements used to build our software, this way we will minimize all the potential damage produced by eventual Software Supply Chain Attacks, aimed to alter these artifacts in order to introduce vulnerabilities.
- Another important objective is to be able to create our projects SBOMs (for audit, or regulatory purposes) and artifact metadata associated stored in our private repository can be used for that. The SBOM will allow us to better manage our software, giving us all the information needed for decision making over production deployments. This also applies to subsequent vulnerability active search in our software and its dependencies, both internal and external. One of the provisions of the Executive Order from US President Biden that we talked about before states that all the software purchased by the federal administration must include an SBOM containing information about all components.
- The last objective is to get the confidence of the users (development and security teams). By using automation in the process we want to avoid introducing unnecessary delays in the lifecycle and to remove and eliminate tedious tasks for your users (that actually are or should be doing) and only require human intervention in edge cases.
Including new artifacts
As a first step, when a development team needs to include a new dependency, they only have to include it in his project by using his configuration management tool (maven, pip, npm, ...). The first time that library is requested (from one of the development team computers if they are using the private repository or in the next CI cycle) the process will be triggered when invoking the private repository to include the dependency. When working with internal artifacts, our software build cycle should provide the information needed to create the metadata when storing the artifact in the private repository.
Metadata
Associated with each artifact we have to store a set of metadata that will help us to better manage its lifecycle, generate its SBOM and to verify that it is suitable for deployment in the production environment. The minimum information we should have is:
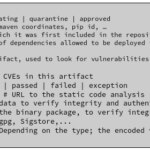
Along with the metadata, we need to store its digest and a cryptographic signature for integrity and authenticity verification. This way we can assure that artifacts have not been tampered with since their inclusion. Services in charge of executing these tasks must be run with an identity intended for this purpose.
External Artifacts
The private repository works in proxy mode behind the public repositories where the libraries are usually published (open source or third party), so when a request comes to include a non-existent artifact, it is downloaded from one of those public repositories and the verification step is triggered, which consists of the following steps:
First a new metadata structure is created and associated with the artifact, the state is set to "new" and, at the same time, a confirmation request is sent to the soliciting team so, if they want to definitely include it in its project, they can trigger the next step. If after evaluating the artifact there is no interest in using it, the team can simply ignore the confirmation request and a periodic task will remove the stale requests after a while. If more teams request the same artifact while in the state "new", they will receive the confirmation request too, so they will be able to continue the process if they so choose. Note that the transitive dependencies will follow the same process.
Second, when any team confirms that it finally wants to use the artifact in production, the state will change to "validating". The security team will be informed that a new dependency has been requested and it is in validation, and the following automatic tasks will be launched:
- Artifact’s origin and integrity verification. Some public repositories are already providing this service but, in other cases, an ad-hoc development will be required, or even human intervention, to get the signature provided by the library developers. At this moment, there is an ongoing Open Source project, Sigstore, that is in its beginnings and that provides services to manage certificates, sign and publish artifacts, and that could prove useful to ease these tasks. The result is stored in a metadata field ("artifact-origin"). If it is not possible to obtain that data it could be replaced by an auto generated digest and signature so we can verify, at least, that the artifact has not been tampered with since its inclusion in the private repository.
- Source code static analysis. This task is important because it provides us with valuable information about possible defects or bad coding practices that can eventually generate vulnerabilities in a future. In the same way we do with our source code, we can download the source code used to generate the binary and analyze it using the same tools. We can develop a language-dependent service that can search for the source code (i.e. in maven central, source code is usually stored alongside the binaries, or npm and pip usually have metadata with the repo URL and commit or tag, download it and analyze it. The result is stored in metadata fields ("static-analysis" y “static-analysis-report”) so it can be consumed later.
- Guess a CPE identifier or equivalent and any published vulnerability list that could exist. If it is not possible to generate the identifier, an alert must be generated to the security team so they can, in collaboration with development teams, compute the identifier by hand. If a valid CPE is obtained, the vulnerability list can be computed. The result is stored in metadata fields ("vulnerability-list" y "CPE").
The three steps can be triggered in parallel asynchronously and, once finished, update the metadata in the corresponding artifact. Once all of them are finished successfully, the state will change to "approved", but if one of them fails, it will change to "quarantine" and it will be notified to the security and solicitant teams so they can act correspondingly. Although all tasks are equally important, it should be possible to choose if all are required or simply make a scoring based on the result, and use that value instead the state to verify if the artifact is valid.
CPE is an identifier used in the NVD database, in which vulnerabilities found in all kinds of components are published. Its coverage on the open source libraries is quite limited (less than 20% of libraries have an assigned CPE), and it is difficult to calculate the CPE from the naming of the libraries (in this article you can learn more about this topic). This task will be, without any doubt, the one which will need more human interaction, but all repositories tend to have a hierarchical structure so once we have the CPE for the first version of an artifact, there will be no need to calculate it again, and we can reuse the same prefix for all the other versions to come.
Different programming languages tend to provide mechanisms to help with CPE determination so, in some cases, it will be feasible to do it in an automatic manner. When it is not possible to guess the CPE, we still have available other alternative methods we will cover in the Vulnerabilities monitorization chapter.
Lastly, it is worth to remind that all these tasks should run under an identity authorized to register the changes in the repository and to issue a valid signature of the metadata so it can be later verified.
Internal artifacts
This case is the easiest case, because we have full control over our own software development life cycle. The build process of internal artifacts should have the same steps mentioned above; source code static analysis, CPE generation (if we want it to be public), artifact digest and signature to guarantee integrity and authenticity, ...; prior to be published in the private repository.
The publishing process for internal artifacts must generate and assign the same metadata as the one associated to external artifacts, so they can be treated the same way as an external artifact.
Although there is no need to generate a CPE for internal artifacts, it is recommended to do so. Generally, internal artifacts are not suitable for vulnerability analysis, but if they are published as OSS it could be necessary to manage this point.
In this case the CI tooling (which is in charge of building and publishing the artifacts) must also be run with an identity authorized to store the artifact and record its metadata and to generate its digest and a valid signature.
Exceptions
An artifact should only be deployed in production only if it and all its dependencies have an "approved" state. We all already know that this only occurs in an ideal world, but in real life there are several cases in which we have to deploy even if the software doesn’t meet all the conditions or cases in which a vulnerability in a dependency doesn’t apply to our project (because we don’t use the functionality with that vulnerability). For these reasons we need a way to manage exceptions. This process should validate that the reasons for which the exception is requested are true and have verification mechanisms (using tests, for example) to ensure that a future change won’t invalidate the exception.
Information related to the exceptions is stored in the metadata (using the label "exceptions") which contains the list of exceptions matching the IDs of the artifacts on which it depends on and that are not "ready for deployment"; this way, the CI/CD pipeline can make decisions when deploying artifacts.
Every exception record must have additional information about who requested it, who approved it, the reason for the exception and the justifications provided. This information should be available to the CI/CD tooling and be verifiable (again, with cryptographic signatures) to avoid tampering going unnoticed.
Vulnerability monitorization
Having an artifact analyzed and secured doesn’t guarantee that a component is free of vulnerabilities. In the future, vulnerabilities could be discovered, so we need to take measures.
Once in the "approved" state, an artifact is eligible to be deployed in production, and we have to establish a process that allows us, both scheduled and on demand, to launch a vulnerability analysis over artifacts stored in the repository. Should a vulnerability be detected on an artifact, we have to change its state to “quarantine”, and fire an alert to the security team and to all the development teams that make use of such artifact, in order to verify if the threat is real and act consequently, either adding an exception if the vulnerability doesn’t apply to our project or making an urgent deployment, or starting to replace or repair the vulnerability.
As we have mentioned before, there could be cases in which we will not be able to make a vulnerability analysis on all the artifacts in the repository (i.e. internal artifacts, or those that don’t have an assigned CPE). There are some additional mechanisms that allow us, for some programming languages, to search for vulnerabilities. Tools like OWASP Dependency Check, and the Security Advisory bulletins of npm or pip, could be integrated in our processes as an alternative to the NVD database, when no CPE exists for the library we are using. In BBVA Innovation for Security we are currently working on a project sponsored by OWASP, Patton, that is intended to provide these services.
Using the metadata in the CD pipeline
Once we have all our artifacts cataloged and with the necessary information, we will see how we can use them appropriately to manage deployment cycles.
All this information can be used for the generation of the SBOM of our software, so that it can be generated for audit requests.
At the time of deploying a component, the CI / CD engine must access the repository and verify the integrity and authenticity of the metadata, later it will validate that the component is in the correct state before starting its deployment. To do this, you must go through the list of dependencies (almost all project configuration management tools include the ability to list direct and transitive dependencies) and verify, in the same way as we have done with the component, that its metadata is authentic and that they are in the correct state, or that there exist authorized exceptions for them.
There are cases in which it only makes sense to stop the process in the case of production uploads, allowing the artifacts to be deployed in the previous environments even when having known vulnerabilities, vulnerable dependencies or when verification is still pending. This must be parameterizable in the DC circuit.
Recommendations
- We must consider as dependencies not only the libraries that we use within our software, but also all the auxiliary programs that are used during the build phase (compilers, clients for other auxiliary tools, ...) since they may also contain vulnerabilities (the aforementioned Codecov case).
- Never use a directly downloaded component during the software build phase, all dependencies must reside in a repository where they can be analyzed and correctly cataloged before use. This procedure would prevent attacks like the recent one to Codecov.
- This process is designed to run within the development cycle and automatically, so that when the software that incorporates the dependency is ready to be deployed to production, all dependencies are already approved. It's a good "selling" point for the development, security, auditing, and compliance teams, as it could free those teams up from time-consuming manual tasks.
- It is advisable to restrict access to the outside to all CI/CD tools, so that we can ensure that all the components used to generate and promote the software to production are properly inventoried and controlled.
- The process includes the use of exceptions for reasons of urgency, in these cases it is convenient to generate an annoying reminder that we have a "dangerous" element in production to motivate the replacement just when a version that fixes the bugs is released.
- There are already external tools that could be used for some of the dependency analysis tasks (e.g., GitHub’s Dependabot) evaluate if they can be used.
- Using the metadata stored in the repository, it is trivial to generate a service that, given a software component, obtains the list of dependencies and their status (and this is just a SBOM), or one that allows identifying those that are affected by a vulnerability in a dependency.
- Some public repositories (such as maven central) have a mechanism to verify the identity of those who publish artifacts in their repositories, as well as the assignment of identities for said artifacts (maven coordinates). It would be ideal if this procedure could be imitated on other platforms. This would allow us to have unique identifiers for all the libraries we use in building software (a simple hash of the published artifact could suffice). It is in our hands to work to ensure that all platforms adopt these good practices.