Gestión de dependencias del software
Tras los incidentes de los últimos meses (SolarWinds , Codecov ,...) cada vez se va haciendo más patente la necesidad de tener inventariado y controlado el listado de todos los componentes con los que construimos nuestro 'software', así como de fortalecer el proceso con el que lo construimos.

Ese listado de componentes de nuestro software es lo que se conoce como SBOM (Software Bill of Materials), y es un elemento clave para la gestión de nuestra cadena de suministros, que es uno de los posibles puntos de entrada de vulnerabilidades en nuestro software, tal y como han demostrado los incidentes anteriormente comentados.
Una buena prueba de la importancia de securizar el SBOM es la Orden Ejecutiva emitida el pasado mayo por el presidente Joe Biden, que impondrá nuevos y estrictos estándares para cualquier software que el gobierno federal adquiera, y entre los que se incluyen algunos destinados a mejorar la seguridad en la cadena de suministro de componentes software (Software Supply Chain).
Introducción
En el presente artículo vamos a hacer una propuesta, sin entrar en detalles de implementación, de un proceso para la gestión de las dependencias de nuestro software, de cara a reducir al máximo la probabilidad de encontrarnos con problemas derivados de vulnerabilidades existentes en las mismas y que nos permita reaccionar con velocidad ante las posibles amenazas que puedan surgir en el futuro. En ningún caso conseguiremos eliminar dichos problemas completamente, pero será una ayuda para poder tomar decisiones de manera informada y actuar con celeridad cuando surjan las amenazas.
¿Que necesitamos?
De cara a poder implementar el proceso vamos a enumerar una serie de elementos y configuraciones necesarias.
- Los componentes, o artefactos, software (ya sean productos principales o sus dependencias) suelen almacenarse en los denominados repositorios de artefactos. Para tener el máximo de garantías sobre el origen e integridad de dichos artefactos debemos disponer de un repositorio de artefactos privado, donde se almacenarán todos los componentes usados para la construcción de nuestro software.
- Este repositorio debería permitir asignar metadatos a los artefactos, dichos metadatos serán usados para hacer el inventario y el 'enforcement' del despliegue. En caso de que el repositorio no disponga de esta funcionalidad se puede construir un servicio que permita almacenar y recuperar toda esta información e integrarlo. También es necesario que sea capaz de generar eventos cuando se modifican (alta, baja, modificación) dichos artefactos.
- La herramienta de CI/CD (porque ya nadie construye y despliega software de manera manual, ¿verdad?) usada para construir y desplegar nuestro software solo tendrá acceso al repositorio privado y, además, en condiciones normales, será el único con permiso de escritura en el mismo, para evitar que nadie pueda reemplazar o añadir software de manera fraudulenta y nos permitirá controlar que sólo se usan artefactos verificados. Dicha herramienta usará los metadatos asociados a los artefactos para poder verificar y tomar decisiones sobre el despliegue del software construido.
- Nuestros desarrolladores deberían usar el repositorio privado en vez de usar directamente los públicos, aunque no es obligatorio. El proceso que describiremos no impondrá limitaciones en el acceso a dependencias en tiempo de desarrollo, con lo que no supondrá retrasos para, por ejemplo, evaluar distintas alternativas; sin embargo, usarlo desde las fases tempranas del desarrollo sí que permitirá acelerar todo el proceso de verificación de las dependencias, ya que se conocerán desde el primer momento.
Descripción del proceso
Antes de comenzar con la explicación del proceso vamos a exponer los objetivos del mismo:
- El proceso busca tener inventariado, verificado y protegido todo aquel elemento que se usa para la generación de nuestro software, de esta manera podremos minimizar los posibles daños ocasionados por los ataques a la cadena de suministros (Supply Chain Attacks) que buscan alterar dichos artefactos para introducir vulnerabilidades.
- Otro objetivo importante es poder generar el SBOM de nuestros proyectos (por ejemplo, de cara a auditoría) y para ello podemos usar los metadatos asociados a los artefactos del repositorio privado. El SBOM nos permitirá gestionar más eficientemente nuestro software, dotándonos toda la información necesaria para la toma de decisiones en el despliegue y para la posterior búsqueda activa de vulnerabilidades en nuestro software y todas sus dependencias, internas y externas. Una de las disposiciones, provocada por la orden ejecutiva del presidente Biden que comentábamos al inicio, es la de exigir el SBOM de los desarrollos contratados por la administración.
- Por último queremos buscar la aceptación de sus usuarios (equipos de desarrollo y seguridad). La automatización del proceso busca evitar introducir retardos en el ciclo de vida y eliminar tareas tediosas para sus usuarios (que actualmente están o debieran estar ejecutando) y solo debería requerir de intervención humana en pocos supuestos.
Inclusión de nuevos artefactos
Como primer paso, cuando un equipo necesita incorporar una nueva dependencia externa, tan solo debe añadirla a su herramienta de gestión de configuración del proyecto (maven, pip, npm,...). La primera vez que se use esta librería (en los equipos de los propios desarrolladores si están usando el repositorio privado o en el siguiente ciclo de CI) el proceso se disparará al solicitar al repositorio privado dicho artefacto. En el caso de artefactos internos nuestro ciclo de construcción debería proporcionar la misma información al almacenar el artefacto en el repositorio.
Metadatos
Asociado a cada artefacto debemos almacenar un conjunto de metadatos que nos permita gestionar su ciclo de vida, generar el SBOM y verificar que es apto para ser desplegado en producción. El mínimo de información debería ser:
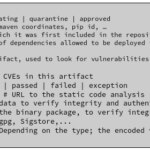
Junto con los metadatos es necesario almacenar su 'digest' y una firma criptográfica para permitir verificar la integridad y autenticidad de los mismos. De esta manera nos aseguraremos de que no se ha manipulado dicho artefacto de manera maliciosa. Los servicios encargados de ejecutar las tareas de nuestro proceso deben hacerlo con una identidad destinada a este fin.
Artefactos externos
El repositorio privado trabaja en modo proxy de los repositorios públicos donde normalmente se publican las librerías ('open source' o de terceros), así que cuando llega una petición para un artefacto que no existe, este es descargado desde uno de esos repositorios públicos configurados y se dispara el proceso de verificación, que consta de los siguientes pasos:
En primer lugar se crea la estructura de metadatos asociada al artefacto y pasa al estado nuevo, a la vez que se envía una petición de confirmación al equipo solicitante para que, en caso de querer seguir adelante con su uso, pueda disparar la verificación. Si después de evaluar el artefacto no se quiere adoptar su uso simplemente se ignora la confirmación y un proceso periódico eliminará los artefactos en estado nuevo pasado un tiempo. El resto de equipos que soliciten un artefacto que ya esté en este estado recibirán también la petición de confirmación, por si el primero en solicitarlo decide no seguir adelante. Hay que tener en cuenta las dependencias transitivas, el proceso deberá ser el mismo para todos los artefactos nuevos que se incorporen como dependencias del solicitado (dependencias transitivas).
En segundo lugar, cuando algún equipo confirme que finalmente quiere usar para producción el artefacto, se cambiará el estado a validando, el equipo de seguridad será informado de que existe una nueva dependencia en validación y se lanzarán tareas automáticas para:
- Verificar la procedencia e integridad del artefacto. Algunos repositorios públicos ya proporcionan este servicio, en otros casos podría ser necesario realizar un desarrollo 'ad-hoc' o requerir intervención manual para acceder a la firma proporcionada por los desarrolladores. Hay un proyecto 'open source' en marcha, Sigstore, que actualmente está en fase inicial de desarrollo que proporciona mecanismos de publicación y verificación de artefactos y que podría simplificar este proceso. El resultado se almacena en un campo de los metadatos ("origen-artefacto"). En caso de no ser posible la tarea puede generar el 'hash' y firma de manera local para poder verificar, al menos, que el artefacto no se ha modificado desde su inclusión en el repositorio privado.
- Análisis estático del código fuente. Este análisis es importante porque nos proporciona información sobre posibles defectos o malas prácticas de codificación que pueden provocar futuras vulnerabilidades. Igual que hacemos con nuestro código podemos descargar el código fuente a partir del cual se generó el artefacto y ejecutar el análisis. Podemos implementar un servicio capaz de localizar el código fuente (por ejemplo, en mavencentral se suele almacenar, o los metadatos de npm y pip suelen tener la URL del repo y el 'commit' o etiqueta correspondiente) y lanzar el análisis. El resultado se almacena en los metadatos (análisis-estático y análisis-estático-informe) para su posterior consumo.
- Determinación de identificador CPE o equivalente y análisis de vulnerabilidades publicadas. Si no es posible determinar el identificador se debe generar una aviso al equipo de seguridad para que intervenga, en colaboración con los equipos de desarrollo, de manera manual en la determinación del mismo. Si fuera posible conseguir el identificador se recuperaría la lista de vulnerabilidades, de existir. El resultado se almacena en los campos de los metadatos (análisis-vulnerabilidades y CPE).
Los tres pasos se pueden disparar de manera asíncrona y en paralelo y, una vez finalizados, actualizan el estado de los metadatos del nuevo artefacto. Una vez finalizados todos de manera satisfactoria el estado del artefacto cambiará a estado aprobado, pero si falla alguno de ellos el estado se actualizará a cuarentena y se notificará a los equipos de seguridad y solicitantes para que puedan tomar medidas y actuar de manera manual. Aunque todas las tareas son importantes se debería poder elegir si todas son requeridas o simplemente hacer un cálculo de 'scoring' a usar posteriormente (en vez de verificar si está aprobado, comprobar si el 'scoring' es inferior a un valor dado).
El CPE es un identificador usado en la base de datos NVD donde se publican las vulnerabilidades encontradas para todo tipo de componentes. Su cobertura en el campo de las librerías software es limitado (menos de un 20% de las librerías tienen CPE asignado), y su determinación a partir de los datos de la propia librería suele ser complicado (en este artículo se puede aprender más). Esta tarea será, probablemente, la que mayor intervención humana requiera, aunque todos los repositorios suelen tener una estructura jerárquica con lo que una vez determinado para la primera versión de un artefacto puede reutilizarse para las posteriores versiones.
Los distintos lenguajes de programación suelen proveer de mecanismos para ayudar en la generación del CPE, así que en algunos casos será posible hacerlo de manera automática. Cuando no es posible determinar el CPE podemos usar alternativas recogidas en la sección de monitorización de vulnerabilidades.
Por último recordar que todo este proceso debe ser gestionado por un servicio que tenga una identidad autorizada para registrar los cambios de estado (para auditoría) y la generación de una firma válida de los metadatos para su posterior validación.
Artefactos internos
Este caso es más sencillo, ya que nosotros tenemos el control absoluto sobre los componentes desarrollados por nosotros mismos. El proceso de generación de artefactos internos debe contar con los mismos pasos citados anteriormente; análisis estático de código, identificación CPE (si lo queremos hacer público), generación de firma para verificación de origen e integridad,...) previo a ser publicados en el repositorio de artefactos privado.
El proceso de publicación de los artefactos internos debe encargarse de la generación y asignación de los metadatos asociados y de su publicación, de manera que pueda ser tratado de la misma manera que uno externo.
Para los artefactos generados internamente no hay necesidad de CPE (aunque sería recomendable hacerlo) por lo que el proceso de análisis de vulnerabilidades no aplicaría (salvo que queramos publicarlo como OSS).
En este caso el motor de CI (que debe ser el encargado de la construcción y publicación de artefactos) también debe ejecutarse con una identidad que le permita registrar los cambios de estado (para auditoría) y la generación de una firma válida de los metadatos para su posterior validación.
Excepciones
Un artefacto solo debería poder ser desplegado en producción cuando obtenga un estado aprobado y todas sus dependencias también lo tengan. Todos sabemos que esto es un ideal y que en la vida real existen casos en los que es necesario desplegar aunque no se cumplan todas las condiciones, o en los que una vulnerabilidad no aplica en nuestro proyecto (porque no se usa la funcionalidad que contiene la vulnerabilidad); con lo que debe existir un procedimiento para solicitar excepciones para un componente. Dicho procedimiento debería validar que los motivos por los que se solicita la excepción son ciertos y contar con un mecanismo de verificación (mediante tests, por ejemplo) para asegurarnos de que en un futuro cambio no invalida dicha excepción.
La información asociada a las excepciones se almacena en los metadatos (mediante la etiqueta excepciones) que contiene el listado de 'ids' de artefactos de los que depende y que no están en estado aprobado; de esta manera el 'pipeline' de CI/CD puede permitir el paso.
Para cada excepción se debe contar con información adicional sobre quién solicitó y autorizó la excepción, el motivo de la misma y las justificaciones aportadas. Esta información debe estar disponible y poder ser verificable (de nuevo, con firma criptográfica) para evitar manipulaciones.
Monitorizar vulnerabilidades
El haber analizado y asegurado un componente no descarta que en un futuro puedan descubrirse nuevas vulnerabilidades en los mismos con lo que es necesario tomar medidas para que en el caso de que aparezcan podamos reaccionar de manera adecuada.
Una vez en estado aprobado un artefacto es elegible para ser desplegado en producción y debemos establecer un proceso automático que permita, de manera periódica y bajo demanda, realizar un análisis de vulnerabilidades en los artefactos del repositorio. En el caso de que se detectara alguna sería necesario cambiar su estado a cuarentena y disparar una alerta para los equipos de seguridad y a todos los usuarios de dicho artefacto para verificar si la amenaza es real y poder actuar en consecuencia, bien añadiendo una excepción si la amenaza no aplica, bien iniciando el proceso de sustitución/reparación de la vulnerabilidad.
Como hemos dicho anteriormente, habrá casos en que este proceso no se pueda realizar para todos los artefactos del repositorio (por ejemplo, artefactos internos o aquellos que no cuenten con CPE). Hay que saber que existen mecanismos adicionales que nos permiten, para algunos lenguajes, la consulta de vulnerabilidades. Herramientas como OWASP Dependency Check, Security advisories de npm o de pip pueden ser usadas para integrar en nuestro proceso alternativas a la base de datos NVD para cuando no existe un CPE para la librería que estamos usando. En BBVA Innovation for Security estamos trabajando actualmente en un proyecto auspiciado por OWASP, Patton, destinado a poder proporcionar estos servicios.
Uso de los metadatos en el circuito de CD
Una vez que ya tenemos todos nuestros artefactos catalogados y con la información necesaria veremos cómo podemos usarlos apropiadamente para gestionar los ciclos de 'deployment'.
Toda esta información puede usarse para la generación del BOM de nuestro software, de manera que puede ser generada para los procesos de auditoría.
En el momento de desplegar un componente el motor de CI/CD debe acceder al repositorio y verificar la integridad y autenticidad de los metadatos, posteriormente validará que el componente se encuentra en el estado correcto antes de comenzar con su despliegue. Para ello deberá analizar cada una de las dependencias (casi todas las herramientas de gestión de configuración de proyectos incluyen la capacidad de listar dependencias directas y transitivas) y verificar, de la misma manera que se ha hecho con el componente, que sus metadatos son auténticos y que se encuentran en el estado adecuado, o que existen excepciones autorizadas.
Hay casos en los que solo tiene sentido parar el proceso en el caso de las subidas a producción, permitiendo que los artefactos se desplieguen en los entornos previos aún conteniendo vulnerabilidades, dependencias vulnerables o en proceso de verificación. Esto debe ser parametrizable en el circuito de CD.
Recomendaciones
- Hay que considerar como dependencias no solo las librerías que usamos dentro de nuestro software, sino también todos los programas auxiliares que se usan durante el proceso de construcción (compiladores, clientes para otras herramientas, ...) ya que también pueden contener vulnerabilidades (el caso de Codecov antes mencionado).
- Nunca usar un componente descargado durante la construcción del software, todas las dependencias deben residir en un repositorio donde puedan ser analizadas y correctamente catalogadas antes de su uso. Este proceder evitaría ataques como el de Codecov.
- Este proceso está diseñado para ejecutarse dentro del ciclo de desarrollo y automáticamente, de manera que cuando el software que incorpora la dependencia esté listo para desplegarse en producción todas las dependencias estén aprobadas. Es un buen argumento de venta para los equipos de desarrollo, de seguridad, de auditoría y de cumplimiento normativo, ya que podría liberar a dichos equipos de tareas manuales que consumen mucho tiempo.
- Conviene restringir el acceso al exterior de todas las herramientas de CI/CD de manera que podamos asegurar que todos los componentes necesarios para generar y promocionar el software a producción se encuentran debidamente inventariados y controlados.
- El proceso incluye el uso de excepciones por motivos de urgencia, en estos casos conviene generar un recordatorio "molesto" de que tenemos en producción un elemento “peligroso” para motivar a la sustitución cuando haya versiones que arreglen los fallos.
- Ya existen herramientas externas que podrían usarse para algunas de las tareas de análisis (por ejemplo, Dependabot), evaluar si se pueden usar.
- Con los metadatos que se tienen almacenados es trivial generar un servicio que, dado un componente software, obtenga el listado de dependencias y su estado (el SBOM), o uno que permita recuperar los que se ven afectados por una vulnerabilidad en una dependencia.
- Algunos repositorios públicos (como maven central) tienen mecanismo para verificar la identidad de los que publican artefactos en sus repositorios, así como la asignación de identidades para dichos artefactos (coordenadas maven). Sería ideal que se pudiera imitar dicho proceder en otras plataformas. Esto nos permitiría contar con identificadores únicos para todas las librerías que usamos en la construcción de software (podría bastar con un simple 'hash' del artefacto publicado). En nuestras manos está trabajar para conseguir que todas las plataformas adopten estas buenas prácticas.