Does GPT-3, the Artificial Intelligence supermodel, work for Spanish bank-customer conversations? Find out how the experiment played out
We tested OpenAI’s GPT-3 (one of the largest Artificial Intelligence (AI) language models ever created) on ten Spanish customer conversations about banking. Without any previous customization, re-training or transfer learning whatsoever, we asked it to generate summaries that would be useful to any bank agent who joins (or retakes) the conversation.

Summary (TL;DR)
GPT-3 (Generative Pre-trained Transformer 3) has demonstrated outstanding performance in very diverse natural language understanding and generation tasks. OpenAI, its creators, have released a limited open API that allows developers to test it.
We test here its ability to generate useful summaries of conversations between a customer and one or more bank agents, a business case that would potentially save time to our customer-facing teams and improve customer experience. The tests were run on ten unedited Spanish conversations about banking extracted from publicly available online forums.
Without any previous fine-tuning, transfer-learning or retraining on the domain’s data, we show that in most cases GPT-3 Davinci manages to generate the desired summaries, identifying the core issue or question, the product or service involved, the recommendation or answer given and its state of completion.
Despite the limited scope of the tests, the results are encouraging and suggest further exploration of the model’s value for our business.
The task: write a good summary of this conversation
Business context
Companies are rapidly shifting towards an increasingly digital business-consumer relationship model. A large amount of the customer’s questions and complaints managed by our bank agents is held in online text channels and is only expected to grow over time, along with voice calls.
Keeping track of these conversations, often involving more than one bank agent across different channels, can prove to be difficult and time-consuming, which suggests turning to automation for assistance. Now, while very high hopes are set on AI to assist humans in charge, the issues involved in these conversations are of the highest importance and sensitivity for our customers, which leaves little room for mistakes.
So, just how ready is the strongest natural language processing (NLP) model ever to date [January 2021] for these tasks? To which extent could it help us during on-going conversations with our customers, full of nuances and complexities? And would an out-of-the-box GPT-3 work on Spanish text without any model customization, re-training or transfer learning whatsoever?
The experiment
Task: given the contents of a conversation (an exchange of text messages between a person and one or more bank agents), generate a summary that is useful to whomever joins and takes over as an agent.
The following criteria was defined to measure the utility of each summary produced:
- Does it get the core issue or question from the customer? (e.g. bank commissions).
- Does it identify the product or service involved? (e.g. a credit card).
- Does it include the recommendation or answer given? (e.g. renegotiate conditions)
- Is the issue fully solved? (i.e. clearly stated by the customer).
Text corpus chosen (in Spanish!)
After evaluating a broad number of public datasets suitable for NLP research, most of them in English, we decided to try our luck on original Spanish text from publicly available online forums about the banking sector. The topics discussed by users in them, along with the flow and dynamics of questions and answers published, kept the closest resemblance to our main business case.
There were certain differences to note though:
- No actual bank agents participate in them, it was just users helping each other. A real bank agent would always ultimately try to retain the customer and would seldom or never publicly disagree with other peer agents.
- Often several solutions were discussed, which differs with the more accurately focused approach of an experienced agent.
- The tone was more informal and the grammar often irregular: lack of capitalization or punctuation, spelling mistakes and typos plagued most of the source Spanish text.
All these aspects would make the summarization task harder than what the actual text from a customer-agent conversation would imply. But on the other hand, the results would be more encouraging if it worked out well against all odds…
Test cases used
- Ten Spanish conversations were chosen from public forums of different lengths and number of participants.
- The text was kept unedited (retaining all typos, lack of capitalization, etc.).
- The conversation subject, possibly hinting some of the answers, was removed from the data. So was all metadata (user id, timestamps, etc.).
- The users replying to the original question were tagged as "Agente 1", “Agente 2”, etc., and the initial user as “Cliente” [Customer].
Some of the conversations selected can be seen below, in "Sample conversations and summaries".
GPT-3 engines tested
OpenAI offers four versions of GPT-3, with different strength vs speed & cost ratios. The engines chosen were:
- Davinci, which with the original 175 [English] billion parameters (175 x 10E9) trained on one of the largest multilingual datasets ever, including Common Crawl and the full Wikipedia, "is generally the most capable engine".
- Curie, a faster engine which, though not as strong as Davinci, "is quite capable for many nuanced tasks like sentiment classification and summarization".
The two engines were tested directly on OpenAI’s playground, given the number of cases to test was not high.
Babbage and Ada, the two more narrow-task-oriented engine variations, were not tested.
Engine settings
All four engines allow setting the following parameters, with a high impact on the text generated. We adapted the values from one of the examples provided by OpenAI in one summarization case:
- Response Length (256): Maximum number of characters to generate.
- Temperature (0.1): We used low temperature since we were requesting straight-forward answers to questions, not creative text generation.
- Top P (1): Controls generation diversity (e.g. 0.5 => consider only half of all likelihood weighted options).
- Frequency Penalty (0.37): To discourage verbatim repetitions.
- Presence Penalty (0): To discourage the likelihood of talking about new topics.
- Best Of (1): To generate a single completion at each call.
OpenAI’s Playground on which the tests were conducted
Zero-shot "learning"
GPT-3 generates text based on some given input or prompt, which can be approached in different ways, as explained in the original paper:
- Few-shot, where the model is given a few demonstrations of the task at inference time as conditioning, but no weight updates are allowed (nor are they in the other approaches).

- One-shot is the same as few-shot except that only one demonstration is allowed, in addition to a natural language description of the task.

- Zero-shot is the same as one-shot except that no demonstrations are allowed, and the model is only given a natural language instruction describing the task.

(Note: the terms few-, one- and zero-shot learning, despite the somewhat confusing terminology, do not imply any modification of the model’s parameters, i.e. its artificial neural network’s weights.)
In a generative model, the prompt, or initial input data, is key to its performance. We adapted the pattern from one of the examples provided by OpenAI, in which the engine, following the zero-shot learning approach, must read an email from a customer and provide answers to a preset list of questions.
The prompt we used was:

This prompt allowed to answer all four questions with a single call by "priming the prompt with the number one to indicate that the answers should relate to the questions that just preceded it".
[ English translation of the Spanish prompt used: ]

Evaluation criteria
The two engines were tested on a subset of the corpus (ten cases), and the outputs produced (or completions) evaluated on the basis of their utility for a bank agent.
This is how each engine was tested:
- The GPT-3 engine was prompted to answer four questions about each case (two times, in order to compare different completions).
- Each answer was ranked between 0 and 1 based on its utility and accuracy.
- For each question we took the lowest score from the two attempts.
- The score for each case is the average of the four answers.
- The overall score for the engine is the average of all ten cases.
Notes:
- When more than one solution was offered to the customer during the conversation, identifying any of them was scored 1.0 (since the question states a single "agent’s recommendation").
- In each case, the global perceived utility of the four answers is taken into account (e.g. a missing detail in answer 2 is not penalized if correctly included in answer 1).
Davinci passes the test
Results
These are the scores obtained by the each engine in each question and their final score (top table), along with the individual results obtained in each of the ten cases (bottom table):
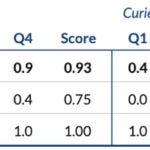
Final scores: Q1-4 reflect performance on each question, while ‘Score’ reflects performance across partial results per case(not the average of left columns).
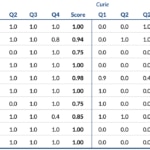
Partial results on each case: Q1-4 reflect the lowest score on each question, while ‘Score’ reflects the lowest total score (not the average of left columns).
The results show that:
- Without any previous fine-tuning, transfer-learning or retraining on the domain’s data, GPT-3 Davinci is able to generate useful summaries of non-curated, original Spanish conversations about banking (score = 0.93 out of 1).
- The issue of the conversations (Question 1) was always correctly identified by this engine.
- The recommendation or answer given by the agent, or at least one of them, (Question 3) was always reflected.
- In one case, despite detecting whether the question from the customer was fully solved (Question 4), it added a wrong reasoning and a low 0.4 score was assigned.
- The product or service involved (Question 2) was missed two times, getting the lowest scores across the four questions.
- The results obtained by Curie (score = 0.27 out of 1) were consistently lower than the more generic model, Davinci. Also, the latter seemed to naturally summarize better without having been explicitly asked to.
Additional comments
- In some cases, when the answer to question 2 (the product or service involved) appeared clearly in the answer to question 1 (the issue of the conversation), the engine didn’t repeat its name and, instead, opted for adding more context or simply repeating the first answer verbatim.
- Sometimes, but not always, the engine would keep on generating text after answering the four questions (e.g. repetitions or variations of the previous text). This was prevented by using Stop Sequences, which can be set before the call.
- The engines were very sensitive to the use of separation blocks; e.g. an extra blank space after the prompt (i.e. “1. ” instead of “1.”) may have catastrophic consequences on the completion generated.
Sample conversations and summaries
A few cases are shown and commented, to give a feeling of what the produced summaries look like. The styles and colors used are:

Case 5
In this conversation up to three agents (in fact other users from the public forum) reply to a question involving banking accounts, cards and discounts. The original user never confirmed their satisfaction with any of the replies, so technically the question can’t be deemed as solved. (Participants are bold-highlighted for readability.)

A second prompt produced this slightly different completion. Notice how the first answer, despite being correct, was not perfectly completed. Also, the third question included this time a long quoted verbatim sequence, a very rare event during the tests.

Case 2
In this shorter conversation a single agent replies to a question about the identity of the company associated with some purchased stock, without further acknowledgement from the customer.
We reflect the worst of the two completions produced, in which all four answers were correct but the reasoning added to the fourth is questionable.

Case 8
This conversation, longer and involving three agents, was one of the lowest ranked cases. The answer to the second question (product or service involved) does include the correct information ("tarjeta de crédito"), but it’s a repetition of the first answer, also correct.
The fourth answer correctly detects that the question has not been deemed solved by the customer, but adds a wrong reason taken from previous text.

Conclusions
While the accuracy of this test on ten conversations can’t be very high, the results obtained are encouraging and suggest further exploration of the model’s value for the targeted tasks (e.g. a benchmark against human level performance).
Further testing on OpenAI’s playground showed that results can be improved through different strategies involving refinements to the settings selected or the initial prompt used (e.g. specific indications like "answer briefly the following questions:").
Also, some sort of sentiment analysis could be easily added to the block, e.g. "How does the customer feel about the issue?". Some quick tests showed promising results (case 9: “5. El cliente se siente confuso y desorientado porque no sabe cuándo se le descontará el dinero de su transferencia periódica.”).
Finally, a complete evaluation of the business value of this technology would need to address aspects like costs, latency, licensing model, etc. which fell beyond the scope of this work.
Acknowledgements
This experiment would not have been possible without the inspiration, suggestions and support of Javier Recuenco Andrés, Pascual de Juan Núñez, César de Pablo Sánchez, Emiliano Martínez Sánchez and the Artificial Intelligence and Hyperscale teams at Innovation Labs.
References
Original OpenAI paper introducing GPT-3: "Language Models are Few-Shot Learners"