¿Funciona GPT-3, súper modelo de inteligencia artificial, en conversaciones en español de clientes de banca? Así fue el experimento
Probamos GPT-3 de OpenAI (uno de los modelos de lenguaje basados en Inteligencia Artificial más grandes jamás creados) en diez conversaciones de clientes sobre banca en español. Sin ningún tipo de adaptación previa, re-entrenamiento o aprendizaje por transferencia, le pedimos generar resúmenes que serían útiles para cualquier agente de banca que se una (o retome) la conversación.

Resumen (TL;DR)
GPT-3 (‘Generative Pre-trained Transformer 3’) ha demostrado un rendimiento sobresaliente en tareas muy diversas de comprensión y generación de lenguaje. OpenAI, sus creadores, han lanzado una API abierta para pruebas de desarrolladores.
Ponemos aquí a prueba su capacidad de generar resúmenes útiles de conversaciones entre un cliente y uno o más agentes de banca, un caso de negocio con el potencial de ahorrar tiempo a nuestros equipos de cara a clientes y de mejorar su experiencia. Las pruebas se realizaron con diez conversaciones sobre banca en español (sin correcciones) extraídas de foros en línea públicamente disponibles.
Sin realizar previamente ningún ajuste fino, re-entrenamiento o aprendizaje por transferencia sobre datos del dominio, mostramos que en la mayoría de los casos GPT-3 Davinci consigue generar los resúmenes deseados, identificando el asunto central o pregunta, el producto o servicio involucrado, la recomendación o respuesta dada y su estado de terminación.
Pese al limitado alcance de las pruebas, los resultados son alentadores e invitan a seguir explorando el valor del modelo para nuestro negocio.
La tarea: escribe un buen resumen de esta conversación
Contexto de negocio
Nos dirigimos rápidamente hacia un modelo de relación empresa-cliente crecientemente digital. Una gran cantidad de las preguntas y quejas de cliente gestionadas por nuestros agentes se realiza en canales de texto en línea y se da por seguro su crecimiento, así como el de las llamadas de voz.
Mantener el hilo de estas conversaciones, que involucran a menudo a más de un agente desde distintos canales, puede resultar difícil y llevar bastante tiempo, lo que sugiere recurrir a la automatización. Ahora bien, pese a las altas expectativas puestas en la IA para asistir a los humanos a cargo, los asuntos tratados en estas conversaciones son de la mayor importancia y sensibilidad para nuestros clientes, lo que deja poco margen para el error.
Así que, ¿cómo de preparado está en realidad el modelo más fuerte de proceso de lenguaje natural (PLN) hasta la fecha [enero de 2021] para estas tareas? ¿Hasta qué punto podría ayudarnos durante las conversaciones en curso con nuestros clientes, llenas de matices y complejidades? Y, ¿funcionaría GPT-3 tal cual se ofrece sobre texto español, sin adaptación, reentrenamiento o aprendizaje por transferecia de ningún tipo?
El experimento
Tarea: dado el contenido de una conversación (un intercambio de mensajes de texto entre una persona y uno o más agentes de banca), generar un resumen que sea útil para cualquier agente que se una (o la retome).
Se establecieron los siguientes criterios para medir la utilidad de cada resumen producido:
- ¿Captura el asunto central o pregunta del cliente? (por ej. comisiones bancarias)
- ¿Identifica el producto o servicio involucrado? (por ej. una tarjeta de crédito)
- ¿Incluye la recomendación o respuesta dada? (por ej. renegociar las condiciones)
- ¿Detecta si el asunto se resolvió por completo? (confirmación clara del cliente)
Corpus de texto elegido (¡en español!)
Tras evaluar un amplio número de conjuntos de datos públicos apropiados para la investigación en PLN, la mayoría en inglés, decidimos probar suerte con textos originales en español de foros en línea sobre el sector de banca disponibles públicamente. Los temas allí discutidos por los usuarios, así como el flujo y dinámica de las preguntas y respuestas publicadas, guardaban el máximo parecido con nuestro principal caso de negocio.
Con todo, había ciertas diferencias a resaltar:
- No participan en ellos agentes de banca reales, eran sólo usuarios ayudándose entre sí. Un agente de banca siempre intentaría retener al cliente y raramente, o nunca, discreparía públicamente con los otros agentes.
- A menudo se discutían varias soluciones, lo que difiere con el enfoque más preciso que seguiría un agente experimentado.
- El tono era más informal y la gramática a menudo irregular: el texto fuente en español estaba plagado de faltas de ortografía, ausencia de mayúsculas o puntuación y errores tipográficos.
Todos estos aspectos harían la tarea de resumir más difícil de lo que implicaría el texto real de una conversación entre cliente y agente. Pero por otro lado, los resultados serían más alentadores si funcionara contra toda posibilidad.
Casos de prueba usados
- Se eligieron diez conversaciones en español en foros públicos de diferentes longitudes y número de participantes.
- Se mantuvo el texto sin editar (reteniendo los errores tipográficos, ausencia de mayúsculas, etc.).
- El asunto o título de la conversación, con posibles pistas para algunas de las preguntas, se excluyó de los datos. Igualmente se hizo con todos los metadatos (identificación de usuario, fecha y hora, etc.).
- Los usuarios que iban respondiendo a la pregunta original se etiquetaron como “Agente 1”, “Agente 2”, etc., y el usuario inicial como “Cliente”.
Algunas de las conversaciones escogidas se pueden ver abajo, en "Ejemplos de conversaciones y resúmenes".
Motores (‘engines’) de GPT-3 probados
OpenAI ofrece cuatro versiones de GPT-3, con diferentes ratios de fortaleza contra velocidad y coste. Los motores elegidos fueron:
- Davinci, que con sus 175 mil millones de parámetros (175 x 10E9) originales, entrenados sobre uno de los conjuntos de datos más voluminosos hasta la fecha, incluyendo Common Crawl y la Wikipedia completa, "es generalmente el motor más capaz".
- Curie, un motor más rápido que, aunque no tan capaz como Davinci, "es bastante capaz para muchas tareas llenas de matices como clasificación de sentimientos y resúmenes".
Los experimentos sobre los dos motores se realizaron directamente en la zona de pruebas de OpenAI (‘playground’), dado que el número de casos no era muy alto.
Babbage, y Ada, las dos variantes del motor orientadas a tareas más específicas, no se probaron.
Ajustes del motor
Los cuatro motores permiten ajustar los siguientes parámetros, con un alto impacto sobre el texto generado. Adaptamos los valores de uno de los ejemplos suministrados por OpenAI para un caso de generación de resúmenes:
- Longitud de la respuesta [‘Response length’] (256): Número máximo de caracteres a generar.
- Temperatura [‘Temperature’] (0,1): Usamos baja temperatura puesto que estamos pidiendo respuestas directas a preguntas, no generación de texto creativo.
- P máxima [‘Top P’] (1): Controla la generación de diversidad (por ej. 0,5 => considerar sólo la mitad de todas la opciones sopesadas según su probabilidad).
- Penalización por Frecuencia [‘Frequency Penalty’] (0.37): Para reducir las repeticiones literales.
- Penalización por Presencia [‘Presence Penalty’] (0): Para reducir la probabilidad de hablar de nuevos temas.
- Mejor De [‘Best Of’] (1): Para generar una sola terminación a cada llamada.
Zona de pruebas de OpenAI (‘playground’) en que se realizaron los experimentos
Zona de pruebas de OpenAI (‘playground’) en que se realizaron los experimentos
"Aprendizaje" sin-ejemplos(‘zero-shot “learning”’)
GPT-3 genera texto basado en el texto de entrada, o pie, que se le da, lo cual puede abordarse de formas distintas, como se explica en el artículo original:
- Pocos-ejemplos (‘few-shot’), cuando se le da al modelo unas cuantas demostraciones de la tarea en tiempo de inferencia, pero no se permiten modificaciones de los pesos (ni tampoco en los otros sistemas).

- Un-ejemplo (‘one-shot’) es lo mismo que pocos-ejemplos excepto que sólo se permite una demostración, además de la descripción en lenguaje natural de la tarea.

- Sin-ejemplos (‘zero-shot’) es lo mismo que un-ejemplo excepto que no se permite ninguna demostración, y al modelo se le da sólo una instrucción en lenguaje natural describiendo la tarea.

(Nota: los términos "aprendizaje con pocos-, un- y sin-ejemplos, pese a su terminología algo confusa, no implican ninguna modificación de los parámetros del modelo, es decir, de los pesos de su red neuronal artificial.)
En un modelo generativo, el pie, o datos de entrada iniciales, es clave para su rendimiento. Adaptamos el patrón de uno de los ejemplos ofrecidos por OpenAI, en que el motor, siguiendo el sistema aprendizaje sin-ejemplos, debe leer un correo electrónico de un cliente y proporcionar respuestas a una lista de preguntas preestablecidas.
La entrada que usamos fue:

Esta entrada permitía responder las cuatro preguntas con una sola llamada al "preparar la entrada con el número uno para indicar que las respuestas deberían referirse a las preguntas que lo precedían inmediatamente".
Criterio de evaluación
Los dos motores fueron probados sobre un subconjunto del corpus (diez casos), y las terminaciones producidas (o ‘completions’) evaluadas sobre la base de su utilidad para un agente de banca:
Así es como se probó cada motor:
- Se pidió al motor de GPT-3 que respondiera cuatro preguntas sobre cada caso (dos intentos, para comparar diferentes terminaciones).
- Cada respuesta fue evaluada entre 0 y 1 según su utilidad y exactitud.
- Para cada pregunta se tomó la puntuación más baja de los dos intentos.
- La puntuación para cada caso es la media de las cuatro respuestas.
- La puntuación global para el motor es la media de los diez casos.
Notas:
- Cuando se ofreció más de una solución al cliente durante la conversación, se evaluó como 1.0 la identificación de cualquiera de ellas (pues la pregunta habla de "la recomendación del agente").
- En cada caso se tuvo en cuenta la utilidad global percibida de las cuatro respuestas (por ej. la ausencia de un detalle en la respuesta 2 no se penaliza si se incluye correctamente en la respuesta 1).
Davinci supera la prueba
Resultados
Éstas son las puntuaciones obtenidas por cada motor en cada pregunta junto con la puntuación final (tabla superior), así como los resultados individuales obtenidos en cada uno de los diez casos (tabla inferior).
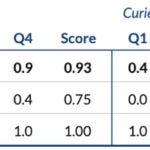
Puntuaciones finales: Q1-Q4 refleja el rendimiento en cada pregunta, mientras que ‘Score’ [Puntuación] refleja la media de resultados parciales por caso (no la media de las columnas a la izquierda).
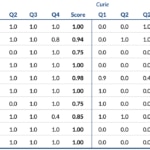
Resultados parciales por caso: Q1-Q4 refleja la puntuación más baja en cada pregunta, mientas que ‘Score’ [Puntuación] refleja la puntuación total más baja (no la media de las columnas a la izquierda).
Los resultados muestran que:
- Sin ningún ajuste fino, aprendizaje por transferencia o reentrenamiento alguno en datos del dominio, GPT-3 Davinci es capaz de generar resúmenes útiles de conversaciones en español sin corregir sobre banca (puntuación = 0,93 sobre 1).
- El asunto de las conversaciones (Pregunta 1) siempre fue identificado correctamente por este motor.
- La recomendación o respuesta dada por el agente, o al menos una de ellas, (Pregunta 3) se reflejó siempre.
- En un caso, pese a detectar si la pregunta del cliente fue completamente resuelta (Pregunta 4), añadió un razonamiento erróneo y se le asignó una puntuación baja de 0,4.
- El producto o servicio relacionado (Pregunta 2) se omitió dos veces dando las puntuaciones más bajas de entre las cuatro preguntas.
- Los resultados obtenidos por Curie (puntuación = 0,27 sobre 1) fueron consistentemente más bajas que las del modelo más genérico, Davinci. Además, éste último parecía resumir mejor de modo natural sin habérsele pedido explícitamente.
Comentarios adicionales
- En algunos casos, cuando la respuesta a la pregunta 2 (el producto o servicio relacionado) aparecía claramente en la respuesta a la pregunta 1 (el tema de la conversación), el motor no repitió su nombre y, en su lugar, optó por añadir más contexto o simplemente repetir la primera respuesta literalmente.
- Algunas veces, pero no siempre, el motor siguió generando texto después de responder las cuatro preguntas (por ej. repeticiones o variaciones del texto anterior). Esto se evitó usando Secuencias de Parada [‘Stop Sequences’], que pueden establecerse antes de la llamada.
- Los motores eran muy sensibles al uso de bloques de separación; por ejemplo, un espacio de más después de la entrada (es decir, “1. “ en vez de “1.”) puede tener consecuencias catastróficas en la terminación generada.
Ejemplos de conversaciones y resúmenes
Mostramos unos cuantos casos con comentarios, para dar una idea de cómo quedaban los resúmenes. Los estilos y colores usados son:

Caso 5
En esta conversación, hasta tres agentes (en realidad otros usuarios del foro público) responden a una pregunta sobre cuentas bancarias, tarjetas y descuentos. El usuario original no llegó a confirmar su satisfacción con alguna de las respuestas, así que técnicamente la pregunta no puede ser considerada como resuelta. (Los participantes están en negrita por legibilidad.)

Una segunda llamada produjo una terminación ligeramente diferente. Nótese cómo la primera respuesta, pese a ser correcta, no se completó perfectamente. Además, la tercera pregunta incluyó esta vez una larga secuencia literal entre comillas, un evento muy raro en estas pruebas.

Caso 2
En esta conversación más corta el agente responde a una pregunta sobre la identidad de la empresa asociada con una acciones adquiridas, sin validación posterior del cliente.
Reflejamos la peor de las dos terminaciones producidas, en que las cuatro respuestas fueron correctas pero el razonamiento añadido a la cuarta es cuestionable.

Caso 8
Esta conversación, más larga e involucrando a tres agentes, fue uno de los casos con peor puntuación. La respuesta a la segunda pregunta (producto o servicio involucrado) sí que incluye la información correcta ("tarjeta de crédito"), pero es una repetición de la primera respuesta, también correcta.
La cuarta respuesta detecta correctamente que la pregunta no ha sido considerada como resuelta por el cliente, pero añade una razón errónea tomada del texto previo.

Conclusiones
Si bien la exactitud de esta prueba sobre diez conversaciones no puede ser muy alta, los resultados obtenidos son alentadores e invitan a continuar explorando el valor del modelo para las tareas elegidas (por ej. una comparativa contra el nivel de rendimiento humano).
Al seguir probando sobre la zona de pruebas de OpenAI vimos que los resultados pueden mejorar con diferentes estrategias de refinamiento de la configuración elegida o del texto de entrada inicial usado (por ej. con indicaciones específicas como "responde brevemente las siguientes preguntas:").
Además, se podría añadir fácilmente algún tipo de análisis de sentimiento en el bloque de preguntas, por ejemplo: "¿Cómo se siente el cliente respecto al asunto?". Unas pruebas rápidas mostraron resultados prometedores (caso 9: “5. El cliente se siente confuso y desorientado porque no sabe cuándo se le descontará el dinero de su transferencia periódica.”).
Finalmente, una valoración completa del valor de negocio de esta tecnología debería abordar aspectos como costes, latencias, modelo de licencias, etc., que caían fuera del alcance de este trabajo.
Agradecimientos
Este experimento no habría sido posible sin la inspiración, sugerencias y apoyo de Javier Recuenco Andrés, Pascual de Juan Núñez, César de Pablo Sánchez, Emiliano Martínez Sánchez y los equipos de Inteligencia Artificial e Hiperescala de Innovation Labs.
Referencias
Artículo original de OpenAI presentando GPT-3: "Language Models are Few-Shot Learners"