El peligro de no interpretar las predicciones de tus modelos
En los últimos meses, en BBVA Next Technologies hemos dedicado cierto esfuerzo a investigar herramientas y técnicas de interpretabilidad de modelos de aprendizaje automático (‘machine learning’). Estas técnicas son de gran utilidad para entender (o hacer entender a otros) las predicciones de un modelo, para extraer información de negocio a partir de un modelo que ha conseguido capturar los patrones subyacentes de interés, y para depurar modelos y estar seguros de que estos toman las decisiones correctas por las razones correctas.
En este artículo explicaremos cómo hemos aplicado estas técnicas para evitar poner en producción modelos fallidos que a priori eran totalmente correctos según los criterios estándar de validación.

Breve introducción a la interpretabilidad
Los modelos de aprendizaje automático han demostrado ser una herramienta extremadamente potente para solucionar problemas en los que hay suficiente volumen de datos disponibles con la calidad necesaria. Hoy en día esta herramienta se utiliza en una gran cantidad de sectores, muchos de ellos de gran relevancia para nuestras vidas, como la medicina, la banca o los coches autónomos.
Uno de los principales problemas de estos modelos es su elevada complejidad, que hace muy difícil entender de forma directa por qué un modelo toma una decisión. Dado que estamos hablando de decisiones importantes, impera la necesidad de encontrar formas de interpretar, aunque sea de manera aproximada, lo que está haciendo un modelo. En este contexto, en los últimos años han surgido (o resucitado) un conjunto de técnicas que permiten, con mayor o menor detalle, entender qué está haciendo un modelo de aprendizaje automático.
Además, desde el punto de vista del científico de datos hay una razón adicional para utilizar técnicas de interpretabilidad: la validación y depuración de modelos. Como se muestra a continuación, muchas de estas técnicas nos pueden ayudar a encontrar errores graves en nuestros modelos o nuestros datos de forma rápida y sencilla, evitando así posibles resultados inesperados.
Caso práctico 1: Detección de daños en coches
Hace algunos meses realizamos una prueba de concepto sobre detección de daños en coches a partir de imágenes. Nos pareció un problema muy interesante, tanto por su aplicación directa a casos de uso del mundo real como tecnológicamente, dado que la complejidad del problema es alta, y ello que nos permitiría aplicar con sentido tecnologías cercanas al estado del arte.
Nos parecía especialmente interesante trabajar con imágenes de calidad reducida, como las que se pueden obtener con un dispositivo móvil de gama media. Esto incrementa la dificultad del problema, pero también abre la puerta a casos de uso más viables.
¿Seríamos capaces de determinar si un coche está o no dañado? ¿Podríamos afinar y localizar el daño (por ejemplo, ser capaces de ver que el daño está en la parte delantera derecha)? ¿Podríamos incluso determinar la magnitud del daño (severo, medio o leve)?
Fig. 1: Caso de uso de detección de daños en coches (fuente)
El reto era realmente complejo debido a dos problemas principales:
- La gran variabilidad de modelos de coche y de posibles daños, así como de condiciones de luz, pose del coche, etc.
- La mala calidad de las imágenes, al ser fotografías hechas por usuarios con su teléfono móvil.
Dedicamos los primeros días del proyecto a investigar si alguien ya había resuelto el problema. Encontramos numerosos 'papers' que enfocaban el problema desde distintos puntos de vista, y dimos con un proyecto ‘open source’ que afirmaba resolverlo con unas métricas excelentes. No nos fiábamos, pero por si acaso nos lanzamos a comprobar si era cierto.

Fig. 2: Métricas publicadas por el proyecto open source neokt/car-damage-detective
El modelo utilizado en el proyecto para detectar si un coche está o no dañado (problema de clasificación binaria) es una red convolucional profunda con arquitectura VGG-16. Ting Neo, autora del proyecto, utilizó los pesos de una red pre-entrenada en Imagenet, sustituyendo las tres capas finales por dos capas fully connected con dropout (0.5).
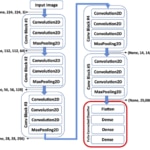
Fig. 3: Esquema de la arquitectura de la red convolucional profunda VGG-16 (fuente)
Así que nos pusimos manos a la obra. Descargamos su conjunto de datos, replicamos el modelo ('coche dañado o no dañado') corrigiendo pequeños bugs y, sorprendentemente, las métricas eran muy similares a las publicadas por la autora. Pero algo no cuadraba. El problema parecía extremadamente complejo, y la solución demasiado "sencilla". Así que el siguiente paso fue validar el modelo en nuestro conjunto de datos. El resultado fue sorprendente. ¡Las métricas en nuestro conjunto de datos eran aún mejores!

Fig. 4: Métricas obtenidas por el modelo 1 en nuestro conjunto de datos
¿Qué estaba pasando? Era posible que hubiésemos sobreestimado la dificultad del problema. Y en realidad era una buena noticia. Habíamos resuelto el problema en muy poco tiempo. Pero antes de cantar victoria, decidimos usar técnicas de interpretabilidad para comprobar qué partes de cada imagen estaba "mirando" el modelo para decidir si un coche tenía o no daños. Si el modelo era correcto, debería fijarse en las partes dañadas de un coche para tomar la decisión de si éste está o no dañado.
En este caso decidimos usar LIME. LIME (Local Interpretable Model-agnostic Explanations) es una herramienta de interpretabilidad que puede utilizarse en cualquier clasificador basado en aprendizaje automático. LIME permite dar una 'explicación' de cualquier predicción de un modelo en forma de modelo lineal con pocas características. Concretamente para el caso de modelos cuyo input son imágenes, LIME crea superpixels de la imagen de entrada y va “encendiendo y apagando” cada superpixel para comprobar su influencia en la predicción final. De esta manera, estima qué superpixels han tenido más influencia (positiva o negativa) en cada predicción.

Fig. 5: Ejemplo de explicación de LIME para un modelo de clasificación de perros y gatos. En este caso, la predicción del modelo es "gato". LIME señala en verde los superpixels más positivamente relevantes para la predicción, y en rojo los más negativamente relevantes (fuente).
Aunque tenemos nuestras reservas sobre LIME por su inconsistencia bajo determinadas circunstancias, la implementación oficial es buena, fácil y rápida de utilizar.
Así que descargamos algunas imágenes de coches de internet, las pasamos por el modelo y utilizamos LIME para ver en qué se estaba fijando éste. A continuación se muestran dos resultados de ejemplo:
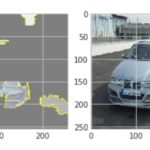
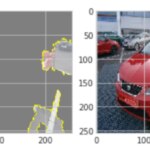
Fig. 6: Ejemplos de resultados de interpretabilidad usando LIME, imágenes de coches y el modelo a evaluar. Como se observa, el modelo se fija principalmente en el entorno, no en el coche.
Como puede observarse en la imagen, el modelo estaba mirando fundamentalmente el entorno, y no el coche, para detectar daños en éste.
Una revisión de los conjuntos de datos disponibles mostró claramente el problema. Gran parte de las imágenes etiquetadas como vehículos "no dañados" en ambos conjuntos de datos eran imágenes de catálogo, con coches impolutos circulando por entornos idílicos y retocados (preciosas carreteras de montaña, una puesta de sol en una carretera costera...). Por el contrario, las imágenes de coches dañados mostraban entornos más mundanos: talleres, parkings, personas mirando el coche y otros coches de fondo. El modelo había aprendido a clasificar entornos, distinguiendo entre entornos de catálogo y entornos más cercanos al mundo real.
Comprobar nuestra hipótesis era sencillo. Si el modelo clasificaba entornos en lugar de coches, debía predecir mal todos los coches no dañados que se encontrasen en entornos cotidianos. Así que hicimos un último conjunto de pruebas con imágenes de coches no dañados en entornos no idílicos. El modelo predijo que todos los coches estaban dañados, confirmando nuestra hipótesis.
Aplicar técnicas de interpretabilidad nos llevó un par de horas y solventó de golpe nuestras dudas sobre el modelo. Este caso puede parecer evidente, y seguramente habríamos llegado a la misma conclusión dedicando más tiempo a analizar el data set. Pero en muchos otros casos los problemas no son tan visuales, y es mucho más difícil darse cuenta de que tu modelo, que aparentemente es bueno, en realidad es un desastre.
De haber puesto el modelo en producción en el caso de uso comentado, la gran mayoría de los coches habrían sido etiquetados como dañados por la aplicación. Otros, dañados pero en entornos más bonitos, podrían haber sido clasificados como no dañados. El modelo habría sido totalmente fallido.
Caso práctico 2: Predicción de ventas en nuevos establecimientos
Juan trabaja para un retailer. Es uno de los responsables de encontrar nuevas ubicaciones para ampliar la red de establecimientos. Afortunadamente Juan dispone de una herramienta que le ayuda a conocer mejor el potencial de venta de cada establecimiento. Cuando Juan ve un local vacío en un barrio de interés, se acerca, saca su teléfono móvil, abre una aplicación y pulsa el botón de "Estimar ventas". La aplicación envía las coordenadas del teléfono a un conjunto de modelos de aprendizaje automático que, basándose en información socio-económica del entorno, en datos históricos y en datos de la competencia, estiman las ventas anuales **del posible nuevo establecimiento.

Fig. 7: Estimación de las zonas de influencia de un establecimiento
El párrafo anterior resume el caso de uso que tuvimos que resolver para un cliente del sector retail. Una de las primeras versiones del modelo obtuvo muy buenas métricas en los datos de test. Se habían generado muchas expectativas sobre la aplicación y había cierta presión para acelerar su desarrollo. Afortunadamente, decidimos invertir algo de tiempo en aplicar técnicas de interpretabilidad al modelo para comprobar que las variables en las que basaba sus predicciones tenían sentido desde el punto de vista de negocio.
El "modelo" es en realidad un conjunto de modelos en cascada, todos ellos basados en árboles. La primera capa de modelos genera características que sirven de entrada a la segunda capa, que es la que realiza la estimación final de ventas.
En este caso optamos por aplicar ‘Permutation Feature Importance’, una técnica que permite conocer la importancia que un modelo da a cada variable de forma global. El resultado fue el siguiente (se han agrupado variables por categoría para simplificar la tabla):

Fig. 8: Tabla resumida de importancia de variables para el modelo principal
Las variables con mayor influencia en las predicciones del modelo eran las características del hipotético establecimiento (tamaño, precio medio de los productos,...). Como el establecimiento aún no existe cuando se usa el modelo, estas características son elegidas por el experto. ¿Por qué el entorno socio-económico o la presencia de competencia apenas tenían importancia para nuestro modelo? ¿Por qué la estimación de ventas de un establecimiento con una configuración concreta no variaba de forma significativa en función de la localización (la predicción era similar para el centro de una gran ciudad que para un pequeño pueblo)?
Reflexionando sobre el resultado y sobre el proceso de obtención de los datos, vimos claramente el problema. Los expertos eligen las características del establecimiento en función del entorno, de la competencia y de su propia estimación de ventas para ese establecimiento. Por ejemplo, si un experto considera que un establecimiento va a vender 1M€ al año, elegirá un local más pequeño que si considera que va a vender 10M€ al año. En nuestro conjunto de datos hay una relación implícita entre las características del establecimiento y la estimación de ventas de los expertos. El modelo detectó esta relación y se aprovechó de ella. Por tanto, teníamos un modelo que siempre daba la razón a nuestro experto. Siempre que el experto introdujese inputs con criterio, el modelo habría dado una buena estimación.
Pero, ¿qué habría ocurrido si hubiésemos puesto este modelo en producción? Los expertos empezarían a fiarse del modelo, pues su funcionamiento era aparentemente bueno. En algún momento, un experto que se fiase del sistema empezaría a experimentar, y vería que establecimientos enormes con tarifas muy altas tienen predicciones de ventas fabulosas. El experto pondría entonces establecimientos lo más grandes posible, independientemente del entorno. Los resultados, por supuesto, serían económicamente desastrosos. Se abrirían establecimientos enormes en pequeños pueblos esperando grandes beneficios de manera errónea.
La solución en este caso fue tan sencilla como eliminar las variables que contenían información del experto del input del modelo. La precisión aparente del modelo se redujo, pero ahora teníamos un modelo que cumplía de verdad su misión.
Compruébalo tú mismo
Hace unos meses preparamos una formación para el Big Data Spain que incluía un módulo de interpretabilidad. En dicha formación propusimos a los asistentes resolver el misterio que explicamos a continuación (y que puede encontrarse resuelto en este notebook).
Primero descargamos un conjunto público de datos de imágenes de perros y gatos, que contiene 25000 imágenes de perros y gatos etiquetadas. Queríamos introducir un sesgo en los datos que fuese sencillo y no demasiado evidente. Así que seleccionamos las imágenes de perros más oscuras y las imágenes de gatos más claras del data set.

Fig. 9: Utilizamos el conjunto de datos Dogs vs Cats de Kaggle (fuente)
Aunque este sesgo puede detectarse de forma relativamente sencilla en una exploración detallada del conjunto de datos, nos pareció lo suficientemente sutil como para servir a nuestro objetivo.
Una vez obtenido un nuevo conjunto de datos sesgado, entrenamos una CNN sencilla que (¡sorpresa!) es capaz de distinguir perros de gatos con una precisión del 100% (puedes ver el entrenamiento del modelo en este notebook).
El reto consistía en que los asistentes, sin conocer el sesgo introducido en los datos a priori, intentasen detectar qué estaba fallando en un modelo que, en apariencia, era perfecto.
Utilizando SHAP, otra gran herramienta para interpretar modelos, los participantes podían obtener de forma sencilla resultados que evidenciaban el problema en el modelo (y en los datos).
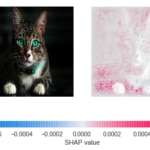

Fig. 10: A la izquierda, las imágenes que se presentaron al modelo. A la derecha, la estimación del valor SHAP de cada pixel. Valores más altos (rosa) indican que el pixel contribuye a que la predicción sea "perro". Valores más bajos (azul) indican que el pixel contribuye a que la predicción sea “gato. Valores cercanos a cero (blanco) indican que el pixel apenas contribuye a la predicción final.
Como puede observarse, en ambos casos nuestro modelo está ignorando casi por completo al gato, nuestro protagonista, y tomando la decisión de si la imagen pertenece o no a un gato observando casi en exclusiva el entorno.
Conclusión
Como se ha ilustrado en los tres casos anteriores, una pequeña inversión en interpretabilidad puede incrementar notablemente nuestra confianza en nuestros modelos antes de ponerlos en producción. El coste es muy pequeño y el beneficio puede ser enorme.
¡Interpretad!
Gracias a Jorge Zaldívar por su aportación con el caso de ventas en supermercados.