Enseñándole negocios a nuestra IA, un caso práctico
Dada una actividad económica excesivamente compleja como para modelar bien sus factores de coste e ingreso, su optimización mediante Inteligencia Artificial (IA) puede dar lugar a una solución académicamente correcta, pero lejos de la optimalidad económica.

En este post se construye una métrica de negocio eficaz sobre un caso práctico real basada en una referencia del rendimiento anterior no cuantificada. La nueva metodología compara nuevos modelos de IA e identifica el óptimo económico, arroje o no las predicciones más precisas.
AI Innovation Labs - Project team:
Alberto Hernández Marcos, César Gallego Rodríguez, David Suárez Caro, Emiliano Martínez Sánchez, Enrique García Pablos, Gema Parreño Piqueras, Germán Ramos García, Jerónimo García-Loygorri, José Luis Lucas Simarro, Leticia García Martín.
¡Este artículo en 1 minuto!
Problema
- Mejorar resultados de un antiguo "recomendador de producto" usando aprendizaje automático.
- Basado en sus resultados hasta ahora (ofertas aceptadas / rechazadas).
- Ignorando los factores de coste y beneficio con precisión (ej: coste de enviar una oferta)
Metodología (versión breve)
- 1. Asumir que el modelo antiguo cubría costes ('break even')
- 2. Estimar el ratio q entre ingreso y coste basado en ello

- 3. Entrenar nuevos modelos sobre resultados pasados (ej. aprendizaje supervisado)
- 4. Ahora, aplicar el ratio q a los resultados de cada modelo y...
- 5. ¡Estimar el % de beneficio teóricamente alcanzabale* que consiguen!
*es decir, si se enviaran ofertas sólo a los clientes que las aceptarán (caso ideal).
Resultados
En casos reales (como el de este artículo) el modelo que "mejor predice" no es siempre el más rentable.
En su lugar, se propone una nueva métrica de negocio (RAP) basada en la metodología de arriba.
La nueva métrica no requiere los factores de coste y beneficio, sino una referencia previa del rendimiento predictivo.
Introducción - El problema de comparar IAs
El desarrollo de proyectos de aprendizaje automático incluye una fase de diseño en la que diferentes modelos son entrenados a partir de datos, probados y comparados antes de su puesta en producción. A menudo se ensayan muy diferentes paradigmas de IA (inteligencia artificial), librerías de 'software', 'frameworks' y estrategias de transformación de los datos, pero al final una única métrica concreta debe aplicarse a todos ellos para una comparativa objetiva que nos señale al mejor.
Si se trata de inteligencia, ¿no basta elegir el modelo que "más acierta"?
Pues no siempre. En principio, cuanto más se parezcan las predicciones de un modelo entrenado a los valores reales esperados en nuestros datos (en el contexto de aprendizaje supervisado), más válido será. Sin embargo, comparar modelos de IA por su grado de acierto predictivo (precisión, curva ROC…) puede llevar a engaño en ámbitos de negocio reales. La causa es que la relación costo beneficio de acertar con la clase buscada (una emergencia real, un cliente idóneo) no es comparable a la de fallar (una falsa alarma, un cliente no interesado). Además, teniendo en cuenta que estos sucesos, acertar o fallar, normalmente no están equilibrados (existen más casos de uno que de otro), el problema se agudiza.
Pensemos en un sistema de alarma: el coste de investigar una emergencia finalmente desestimada suele ser mucho menor al daño causado por un percance no identificado. En un ámbito distinto, como el marketing, la comparativa se podría aplicar entre el coste de un envío publicitario fallido y el beneficio perdido al no identificar a un cliente predispuesto. En ambos casos, la importancia de un error predictivo es muy desigual entre las dos clases.
Por esta razón, es muy posible que la métrica finalmente elegida no sea necesariamente de naturaleza "cognitiva" (tasas de acierto como exactitud, precisión, valor-F...), sino que sintetice el objetivo prioritario de negocio para el caso de uso (ej: maximizar el retorno de la inversión). En general, ésta puede ir acompañada de otras métricas a satisfacer (ej: límite máximo de latencia en las respuestas, límites aceptables para ciertas métricas de equidad o 'fairness', etc.).
En resumen, la elección se hará en realidad sobre el modelo que maximice la métrica elegida, que si es de carácter financiero, no necesariamente dará la máxima tasa de aciertos.
Entonces, ¿basta con ponderar dichos costes / beneficios sobre las predicciones?
En teoría sí; en aprendizaje supervisado (donde tenemos muestras etiquetadas de los resultados que esperaríamos del modelo), se puede hacer un balance de los aciertos y fallos ponderados por los valores dados. Sin embargo en la práctica, por causas muy diversas, las organizaciones raramente son capaces de proveer cuantificaciones reales y fiables de estos valores. Una de las razones principales es la dificultad de estimar los costos o beneficios 'indirectos' de una acción tomada, más allá de los directamente asociados.
Este artículo propone, sobre un caso práctico real, una metodología sencilla para la comparación de modelos de IA basada en métricas de negocio. La métrica propuesta sólo requiere una referencia base de rendimiento previa no cuantificada económicamente.
Caso práctico real: marketing por eventos
Ilustraremos la metodología con datos reales de una prueba de concepto realizada en el ámbito del "marketing por eventos", donde el objetivo de un modelo recomendador de IA es predecir en tiempo real qué clientes son propensos a aceptar la oferta de un cierto producto, lo que produce el envío de la oferta.
En este caso, compararemos financieramente diferentes modelos de IA contra una referencia base del rendimiento predictivo (no financiero) del anterior modelo en uso.
Escenario original
El sistema previo al entrenamiento de nuevos modelos incluía:
- Un sistema ya en producción que recibía todas la operaciones de tarjeta como eventos en tiempo real (compras, extracción de efectivo, depósitos).
- Un sistema de IA basado en reglas que recomendaba en tiempo real productos financieros apropiados basándose en la información del evento (una transacción de tarjeta) y en datos históricos sobre el cliente.
- Un sistema de recolección de datos que registró toda la actividad durante un cierto intervalo de tiempo: eventos recibidos, ofertas enviadas y resultado final de cada oferta enviada.
El objetivo de la prueba de concepto era validar si mediante aprendizaje automático se podría entrenar un recomendador que diera un rendimiento equivalente o mejor, como alternativa al sistema de reglas. La razón es que los sistemas basados en reglas suelen requerir un mantenimiento muy costoso y su rendimiento decrece cuando el número de reglas integrado es alto.
Referencia base de rendimiento
Tras algo más de dos meses de seguimiento del sistema, se registró una volumetría de cientos de millones de eventos de tarjetas de clientes para algunos de los cuales el sistema de reglas activó el envío de ofertas, y un alto porcentaje de los eventos no generó envíos.
Se optó por enfocar la prueba de concepto sobre las ofertas de uno de los productos bancarios, que contaban con el mayor volumen de datos y una tasa de éxito no demasiado desequilibrada (2,79% de éxito sobre los envíos realizados, lo que está dentro de los estándares del marketing 'retail'). [Es frecuente en ámbitos como marketing o seguridad que la clase buscada (cliente propenso, caso de fraude) se dé con mucha menos frecuencia que la otra, lo que se conoce como desequilibrio o desbalanceo de clases]:
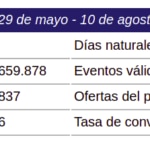
Ésta es la evidencia empírica disponible acerca del rendimiento del sistema de reglas. Sin, cuantificar con precisión dicho rendimiento en términos de negocio implicaría estimar los valores para el modelo de negocio subyacente (costes de envíos, costes indirectos, coste de oportunidad por saturación de canal, ingresos por tipología...), lo que habría acarreado una complejidad inmanejable. En su lugar, una nueva metodología fue ensayada.
Modelos entrenados mediante aprendizaje automático
Se siguieron diferentes estrategias para la preparación de los datos y el entrenamiento de modelos, sobre el conjunto de entrenamiento de unas 148.837 muestras de ofertas etiquetadas como aceptada / no-aceptada, del que:
- 126.087 muestras fueron usadas para entrenamiento.
- 22.750 muestras fueron separadas como conjunto de prueba sobre las que comparar rendimientos.
En total se entrenaron 2.266 modelos en tres "generaciones", que fueron evaluados contra el conjunto de datos de prueba:
- 18 modelos entrenados manualmente, siguiendo diferentes enfoques (regresión logística, árboles de decisión, máquinas de vectores de soporte, etc.).
- 2.212 modelos de redes neuronales artificiales entrenados automáticamente mediante calibrado de hiper-parámetros.
- 36 modelos de regresión logística entrenados automáticamente mediante calibrado de un hiper-parámetro (número de atributos a usar, previamente priorizados).
Para más detalles sobre los modelos, se puede ver el "Apéndice 2. Resumen de modelos entrenados".
Además se incluyeron los siguientes modelos base de referencia para poder ratificar los resultados de los modelos entrenados: 'predicción-siempre-positiva', 'predicción-siempre-negativa' y 'predicción-aleatoria-50%'. (Se espera que los modelos entrenados den resultados mejores que los nulos.)
Metodología para la comparativa financiera de modelos
Para la comparación de los modelos previamente entrenados, por encima de su capacidad cognitiva se deseaba conocer el impacto estimado en el negocio en comparación con el modelo anterior. No disponiendo de una cuantificación realista de los posibles casos, pero sí su tasa de acierto, se estableció la siguiente metodología:
- Conocido el resultado del modelo anterior, estimar el ratio coste / ingreso medio por oferta enviada / aceptada sobre la base de una hipótesis razonable (ej. se parte de una situación de 'break-even', en la que el retorno de la Inversión = 0%).
- Expresar el máximo beneficio teóricamente alcanzable por un modelo (TAP por 'Theoretically Achievable Profit') en función de coste e ingreso medio unitario. (En nuestro caso, TAP se alcanzaría idealmente si se enviase una sola oferta a cada cliente propenso a aceptarla, y todas son efectivas.)
- Definir la métrica RAP (por 'Relative Achieved Profit') como el porcentaje del máximo beneficio alcanzable realmente alcanzado por un cierto modelo. Luego, aplicarla sobre los resultados de cada nuevo modelo a evaluar, eligiendo el más alto de entre todos los modelos.
1. Estimación del ratio entre ingreso y coste unitario medio sobre una hipótesis de rendimiento económico previo
Desconocidos los valores precisos para el coste e ingreso unitario por cada oferta enviada y aceptada, se propone formular una hipótesis razonable sobre el Retorno de la Inversión (ROI por 'Return On Investment') del modelo anterior, por ejemplo:
Hipótesis:
"El modelo anterior recupera exactamente la inversión (punto de ‘break-even’)". Esto significa que ROI = 0.
En general, conocidos los resultados del modelo anterior
- VP=Verdaderos Positivos (número de ofertas enviadas y aceptadas)
- FP=Falsos Positivos (número de ofertas enviadas pero no aceptadas)
- VN=Verdaderos Negativos (número de ofertas no enviadas que no habrían sido aceptadas)
- FN=Falsos Negativos (número de ofertas no enviadas que hubieran sido aceptadas)
Y siendo nuestros valores económicos desconocidos
- c=coste medio de enviar una oferta (coste unitario)
- i=ingreso medio esperado por una oferta aceptada (ingreso unitario)
se puede expresar el ROI del siguiente modo (ver "Apéndice 1. Estimación del ratio entre ingreso y coste unitario como función del ROI" para el desarrollo):
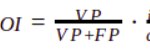
La primera fracción representa la 'precisión' del modelo, y renombrando el ratio entre ingreso y coste unitario, o rentabilidad unitaria, como 'q':
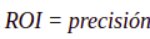
En nuestro caso, los valores de VP y FP del anterior modelo arrojan una precisión de 0,027856, así que para que ROI sea 0 tenemos:
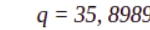
Es decir, los ingresos medios por cada oferta aceptada deben ser unas 35,90 mayores al coste total de enviar cada oferta. Esto significa que si, por ejemplo, el coste unitario 'c' de enviar una oferta fuera de 1,0 $, los ingresos medios esperados i serían de 35,90 $ para cubrir costes exactamente.
Otras hipótesis sobre el rendimiento del modelo anterior, por ejemplo, un rendimiento moderado con ROI = 10%, darían distintos valores de 'q', lo que podría modificar la comparativa de modelos. Se estudia este efecto en "Resultados obtenidos" más adelante.
2. Expresar el máximo beneficio teóricamente alcanzable por un modelo (TAP) en función del coste e ingreso unitario medio
Dados los resultados recogidos para un nuevo modelo, probado sobre cierto conjunto de prueba, el máximo beneficio teóricamente alcanzable (o TAP por 'Theoretically Achievable Profit') se lograría idealmente si el nuevo modelo enviase una oferta a cada cliente propenso a aceptarla (recogido en el histórico del modelo anterior), y ninguna en balde. Este recubrimiento ideal incluiría los aciertos del nuevo modelo más los que debería haber encontrado, o falsos negativos. El beneficio de cada caso sería simplemente el ingreso menos el coste:
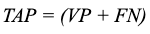
3. Definir la métrica RAP como el porcentaje de TAP obtenido
Hipótesis:
Suponemos que los valores de ingreso y de coste de las muestras del conjunto de datos siguen distribuciones uniformes en que 'i' y 'c' son el ingreso y coste medio respectivamente.
Según esa premisa, cada nuevo modelo arrojará resultados no óptimos según esta expresión para el beneficio (o P por Profit):
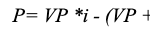
Podemos medir ahora el porcentaje del máximo beneficio alcanzable teóricamente realmente alcanzado por el nuevo modelo, definido como RAP.
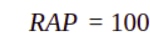
La igualdad, tras algunas transformaciones, queda expresada así:
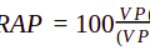
Donde:
VP, FP y FN son los resultados obtenidos por un nuevo modelo sobre un conjunto de prueba (Verdaderos Positivos, Falsos Positivos y Falsos Negativos),
q es el ratio entre ingreso y coste unitario estimado sobre la hipótesis inicial.
La expresión obtenida sólo depende del valor q estimado y de los resultados del modelo evaluado. Es ahora posible aplicarla sobre los resultados de cada nuevo modelo a evaluar, eligiendo el más alto.
Discusión y selección de métricas de negocio
Métrica principal RAP
La métrica principal seleccionada para el caso real fue RAP (porcentaje del máximo beneficio alcanzable) por las siguientes razones:
- 1. Proporciona una valoración del potencial económico de cada modelo independiente del número de muestras, asumiendo que las proporciones de falsos y verdaderos positivos y negativos es invariante al volumen.
- 2. Está acotada en casos óptimos independientemente de la rentabilidad unitaria:
-
- a. Máximo beneficio alcanzable: FP = FN = 0
RAP = 100% independientemente del ratio q.
-
- b. Máxima precisión: FP = 0
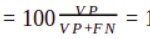
- que es también independiente del ratio 'q'. El resultado queda limitado al valor de la exhaustividad ('recall') del modelo, pudiendo dar muy poco beneficio real.
- 3. Su cota nula es coherente con la rentabilidad esperable de un modelo de la más baja precisión posible, es decir, con VP ≈ 0 .
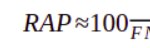
- que será negativo (pérdida económica) bajo el supuesto razonable de que 'q' > 1, es decir que ingreso unitario sea mayor que el coste unitario.
- 4. Dado que la función resulta monótona creciente y acotada entre valores útiles, nos permite comparar modelos probados sobre muestras de datos distintas, asumiendo la premisa de que su distribución estadística es la misma.
Métrica ROI
La métrica de Retorno de la Inversión o ROI (por Return On Investment), pese a cumplir los mismos requisitos de generalidad que RAP, no fue priorizada porque sus valores no indican directamente el volumen de beneficio financiero. Un modelo muy cauto (enviando pocas ofertas muy bien dirigidas) con un ROI porcentual muy alto no necesariamente supera a otro que coseche más beneficio neto a costa de menor precisión y valor de ROI más bajo.
Ejemplo:
El modelo B), pese a tener mayor ROI, dará menos beneficio porque recoge una fracción menor del máximo beneficio alcanzable TAP:
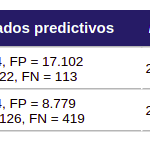
q = 35,90 [hipótesis: el modelo anterior cubría gastos (break even)]
Métrica P
Finalmente, la métrica P (por Profit), o beneficio neto directamente obtenido, no fue priorizada porque su cuantificación requería los valores del coste e ingreso unitario, que no siempre se conocen con precisión debido a los costes ocultos asociados. Además su valor se limita al volumen de la población de prueba, no siendo comparable con modelos sobre muestras distintas.
Durante la exploración sí se calcularon escenarios sobre la base hipotética de 1.0 $ / 35,90 $ para el coste / ingreso unitario, pero su valor y magnitud eran sólo ilustrativos y contextuales a las muestras del conjunto de prueba usado, lo que no proporcionaba la generalidad comparativa de un porcentaje.
Resultados obtenidos
Métricas de IA usadas
Métricas cognitivas
Miden el poder predictivo demostrado por los modelos de IA durante su entrenamiento y prueba (o durante su operación en producción, una vez se da). En nuestra prueba de concepto se recogieron las siguientes métricas:
- Exactitud ('Accuracy')
- Precisión ('Precision')
- Exhaustividad o Sensibilidad / Recuperación ('Recall')
- Probabilidad de Falsa Alarma
- Especificidad ('Specificity')
- Valor-F ('F-score')
Métricas de negocio
Miden los resultados económicamente cuantificables obtenidos por las predicciones de un modelo. En nuestra prueba de concepto, se calcularon las siguientes métricas según la metodología descrita anteriormente:
- Porcentaje del máximo beneficio alcanzable RAP [Métrica principal]
- Retorno de la Inversión (ROI)
- Beneficio B (escenarios sobre valores hipotéticos de coste / ingreso unitario)
Otras métricas no usadas
Existen otras posibles dimensiones o métricas de IA que pueden aplicarse a los modelos entrenados, como:
- Métricas éticas, para garantizar un rendimiento aceptable y confiable de la IA según un cierto conjunto de valores o principios. Un ejemplo son las métricas de equidad, o 'fairness', como la usada en Alphabid, una referencia interna real aplicada al precio dinámico ético.
- Métricas computacionales, midiendo el rendimiento técnico y consumo de recursos infraestructurales, por ejemplo: consumo de potencia de proceso, memoria y recursos de red, almacenamiento de datos, latencias, etc.
En la prueba de concepto actual, sin objetivo inmediato de productivización, no se ha puesto el foco en todos los tipos de métrica para poder profundizar en el equilibrado de las dos seleccionadas: cognitivas / de negocio.
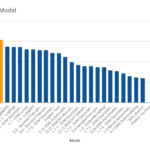
Comparativa de modelos
Se recogieron métricas cognitivas de todos los modelos entrenados y sus resultados se emplearon para computar sus respectivas métricas de negocio. La tabla inferior refleja la clasificación por la métrica principal RAP de los modelos más representativos entrenados más algunas métricas de los modelos base, resaltando los máximos obtenidos en cada métrica. Se puede apreciar que el modelo más rentable no es necesariamente el mejor entrenado.
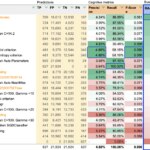
Clasificación de algunos modelos entrenados según la métrica principal RAP, % del máximo beneficio alcanzable. Hipótesis: ROI de partida = 0%. El modelo mejor entrenado no es el más rentable.

Conclusiones
Relevancia de las métricas de negocio
- En el caso real explorado sería imposible identificar el modelo óptimo sin las métricas de de negocio.
El mayor porcentaje del beneficio alcanzable no lo obtiene ninguno de los modelos con mejores resultados cognitivos (precisión, exhaustividad, valor-F…), sino el que pondera adecuadamente el efecto de los aciertos o fallos de las predicciones. Puede verse que el modelo más rentable mejora la rentabilidad del que tiene mejores predicciones en un 5% (del 25,7% al 30,7%).
- A pesar de su significancia en el contexto financiero, el Retorno de la Inversión (ROI) no puede sustituir a la métrica principal RAP.
- Las métricas cognitivas son necesarias durante el entrenamiento de modelos, si bien su capacidad comparativa es generalmente limitada en casos de uso de negocio.
Robustez de la Hipótesis: "el ROI de partida era cero (cubría gastos)"
La hipótesis de ROI de partida sobre la que se estimó el ratio q es arbitraria y puede ser cuestionable; en general, se espera que el ROI sea superior al 0% que asumimos. Por esa razón, se exploró el efecto de diferentes hipótesis sobre la clasificación de modelos en nuestro caso particular y se verificó la estabilidad de la metodología.
En la gráfica inferior se representa un análisis de sensibilidad con el RAP de cada modelo en función de la hipótesis formulada sobre el ROI de partida y el rango de validez del modelo elegido.

Análisis de sensibilidad: Exploración del RAP para cada modelo como función del ROI de partida supuesto. El modelo seleccionado se mantiene como óptimo en un rango muy amplio de hipótesis.
Las conclusiones extraídas son:
- La metodología proporciona estabilidad en el caso real probado. El modelo seleccionado se mantiene como óptimo para hipótesis de ROI de partida entre -15% y +50% aprox., un rango de seguridad muy razonable para el rendimiento previo.
- Para ROI < -15%, tres de los modelos manualmente creados dan mejor resultado económico.
- Para ROI > 50%, en que el coste unitario es muy bajo en relación con el ingreso, los modelos poco discriminantes se imponen, con un máximo en el modelo "tonto" que siempre propone enviar.
Sobre el entrenamiento de modelos
- "La máquina gana": El modelo óptimo surgió de la herramienta de diseño automático, pese al tiempo dedicado al diseño y calibrado manual de modelos, muchos de ellos basados en el mismo algoritmo ganador (Regresión Logística). La aplicación de métodos automatizados de calibrado parece una necesidad para alcanzar la optimalidad.
- Modelos más complejos, como las redes neuronales, fueron entrenados automáticamente sin uso de regularización, razón por la que posiblemente quedaron por detrás de modelos más sencillos. La inclusión de hiperparámetros de regularización en la herramienta de diseño automático (L2, 'dropout'...) mejoraría seguramente los de esta prueba de concepto.
- "Fallar era barato": pese a sus bajos resultados predictivos, el rendimiento del modelo nulo o de línea base que siempre propone enviar no es fácil de superar económicamente, a causa del alto desequilibrio entre el coste atribuido a emitir a una oferta y el ingreso medio esperado. (Evidentemente el modelo nulo no es aplicable en la práctica, pues no tiene en cuenta limitaciones de recursos ni el efecto de saturación de clientes.)
Viabilidad de entrenar un nuevo recomendador
- La prueba de concepto confirma empíricamente la viabilidad de entrenar un nuevo recomendador mediante Aprendizaje Automático con una capacidad predictiva comparable a la del sistema de reglas existente.
- Además, pese a desconocerse los valores de coste e ingreso unitario, se confirma que el nuevo modelo tendría un rendimiento económico al menos comparable, sobre la hipótesis de que el ROI anterior se encontrase entre -15% y +50% (con alternativas razonables para el resto de casos). De hecho, añadiendo la priorización económica que incorpora el modelo seleccionado mediante esta metodología, lo hace más rentable que el sistema de reglas original
Limitaciones y siguientes pasos
En primer lugar, si bien los resultados confirman la viabilidad del Aprendizaje Automático para el caso de uso explorado, no es posible una comparación rigurosa entre el antiguo sistema de reglas y los nuevos modelos. La razón es que los resultados del primero se obtuvieron sobre la población general de clientes, y los de los segundos sobre el subconjunto de clientes preseleccionados por las reglas, con distintas distribuciones estadísticas. Una continuación de la prueba de concepto implicaría la puesta en producción de nuevos modelos y su comparativa real y posible reentrenamiento progresivo.
En cuanto a la nueva metodología seguida, se aplicaron las nuevas métricas de negocio sobre los resultados de los entrenamientos de nuevos modelos. En lugar de esto, un enfoque interesante sería integrar las nuevas métricas directamente en el entrenamiento, por ejemplo definiendo funciones de coste ponderadas según el ratio 'q' entre ingreso y coste unitario (o rentabilidad unitaria). El objetivo sería que los entrenamientos obtuviesen directamente modelos óptimos respecto a la métrica principal.
En términos más generales, si bien la nueva metodología aplicada a este caso real aporta gran valor sobre las métricas cognitivas clásicas de IA, no está probada su estabilidad respecto a la hipótesis inicial en otros casos de uso. Esperamos aprender más en futuras exploraciones sobre nuevo dato.
Finalmente, la hipótesis asumida respecto a los ingresos y costes es que siguen distribuciones uniformes, lo que permite aplicar sus valores medios a las predicciones. En casos donde esto no sea aplicable (por ejemplo, si siguieran una distribución normal), la formulación requeriría una generalización que arrojase rangos de probabilidad, o bien un entrenamiento con costes individualizados por muestra. Un caso de interés podría ser la detección de fraude, en que las cantidades comprometidas en cada operación evaluada tienen una alta variedad.
En cuanto a nuevas posibilidades abiertas a partir de esta línea, un enfoque que podría enriquecer la elección del modelo más rentable y su idoneidad relativa puede ser generalizar la hipótesis de arranque y sus rangos razonables, por ejemplo:
- hipótesis sobre el rango del ROI anterior (ej: "el ROI anterior está entre un 10% y un 20%").
- hipótesis sobre el ratio q entre ingreso y coste unitario (ej: "el valor de una venta de producto es al menos 10 veces mayor a la inversión realizada en dicha oferta").
- hipótesis sobre el ingreso unitario aproximado (ej: "entre 90 $ y 110 $"); sobre esto se podría estimar el máximo coste unitario a partir del cual cierto modelo ya no es rentable.
- otras combinaciones de estas hipótesis.
Finalmente, las métricas de negocio como RAP podrían aplicarse para permitir análisis de coste / beneficio para la cuantificación y priorización de acciones (revisión manual de una alerta, llamada de un agente de CRM) y la planificación de recursos según el balance entre su coste total (nº de especialistas, nº de agentes de CRM) y el impacto en el negocio (pérdida estimada para la alerta, beneficio estimado de la oferta una vez aceptada).
Referencias y agradecimientos
Repositorios de código y herramientas propias usadas:
- Simulación de datos: Khermes
- Transformación de datos: Casterly_rock
- Transformación y agregación de datos: Data refinery
- Calibrado automático de hiperparámetros: BeagleML
Sobre las métricas éticas:
"Reinforcement Learning for Fair Dynamic Pricing"
(by Roberto Maestre, Juan Duque, Alberto Rubio, Juan Arévalo)
Un ejemplo de métricas de equidad, o "fairness", usadas en Alphabid, una referencia interna real aplicada al precio dinámico ético.
"On Formalizing Fairness in Prediction with ML"
(by Pratik Gajane, Mykola Pechenizkiy )
Una comparativa en profundidad de los tipos de métricas éticas y una discusión de su aplicabilidad y limitaciones.
"Delayed Impact of Fair Machine Learning"
(by Lydia T. Liu, Sarah Dean, Esther Rolf, Max Simchowitz, Moritz Hardt)
Sobre la necesidad del modelado temporal de las métricas éticas para una valoración correcta del efecto a largo plazo en la población.
Agradecimientos:
Este proyecto no habría sido posible sin el apoyo y esfuerzo generosamente invertido por nuestros compañeros: Álvaro Herrero, Samuel Vieyra, Roberto Castañeda, Alán Orlando Cruz Manrique, José Alberto López Flores y Julieta Irma Mejía Pérez.
El texto se ha beneficiado (mucho) de la revisión y consejos de Pascual de Juan Núñez (Pasky), Roberto Maestre, Luis Saiz, Noel McKenna, Samuel Muñoz y Jerónimo García-Loygorri.
Apéndice 1. Estimación del ratio entre ingreso y coste unitario como función del ROI
Evidencia empírica: Un modelo anterior ha realizado recomendaciones sobre cierto producto a clientes; algunas de las ofertas han sido aceptadas, y otras no.
Hipótesis: Suponemos que los valores de ingreso y de coste de las muestras del conjunto de datos siguen distribuciones uniformes en que 'i' y 'c' son el ingreso y coste medio respectivamente.
La inversión realizada (costes) y el beneficio obtenido serían:
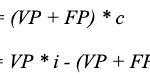
Entonces, el retorno de la inversión (ROI) sería:
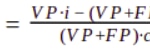
La primera fracción se conoce como precisión, y la segunda, el ratio entre ingreso y coste unitario, se puede renombrar por comodidad como 'q'. La expresión general para el ROI es ahora
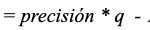
Y podemos ya expresar nuestro valor desconocido 'q' como una función de la precisión conocida y un valor de ROI a estimar (según alguna hipótesis razonable).
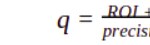
Apéndice 2. Resumen de modelos entrenados
1ª Generación
Diversos modelos entrenados manualmente, siguiendo diferentes enfoques de equilibrado de clases y de selección y transformación de atributos.
Atributos y conjunto de entrenamiento:
- Equilibrado de las clases (SMOTE)
- Selección de atributos (distintos enfoques manuales)
- Transformación e ingeniería de atributos (distintos enfoques manuales)
Algoritmos probados:
- Regresión logística
- Máquinas de vectores de soporte ("Support Vector Machines" (SVM))
- Potenciación del gradiente extrema (XGBoost)
- Árboles de decisión
- Bosques aleatorios (Random Forests)
Tecnología usada:
Librería Scikit Learn, Python, Jupyter.
Resultados:
Se recabaron métricas cognitivas de 18 modelos de entre los aproximadamente 30 entrenados.
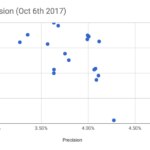
Comparativa por precisión contra exhaustividad de la 1ª generación
2ª Generación
Modelos de Redes Neuronales Artificiales (ANNs) entrenados automáticamente con BeagleML, un prototipo interno para calibrado de hiperparámetros.
Atributos y conjunto de entrenamiento:
- Equilibrado de los datos (SMOTE)
- 8 atributos seleccionados de entre 36 por Eliminación Recursiva de Atributos (RFE)
- Sin ingeniería de atributos
Hiperparámetros libres (ANN):
- Profundidad: 1, 2, 3 capas
- Neuronas por capa: 40, 100, 200
- Tasa de aprendizaje (learning rate): 0,1 - 0,001
- Función de activación: Unidad lineal rectificada (ReLU) / Sigmoide
- Tamaño del lote: 50.000 - 10.000 muestras
- Repeticiones (epochs): 50, 75, 100
Hiperparámetros fijos:
- Optimizador: Adam
- Función de salida: Sigmoide (umbral = 0,5)
- Exactitud de corte (cut-out accuracy): 0,9
Tecnología usada:
TensorFLow, Python.
Resultados:
Se entrenaron 2.212 modelos de los que se recabaron métricas cognitivas.

Comparativa por precisión contra exhaustividad de la 2ª generación
3ª Generación
Modelos de Regresión Logística entrenados automáticamente.
Atributos y conjunto de entrenamiento:
- Equilibrado de los datos (SMOTE)
- De 1 a 36 atributos priorizados por Eliminación Recursiva de Atributos (RFE)
- Sin transformación o ingeniería de atributos
Hiperparámetros libres:
- Número de atributos: 1 - 36
Hiperparámetros fijos:
- (valores por defecto de las librerías usadas)
Tecnología usada:
SciKit Learn, Python.
Resultados:
Se entrenaron 36 modelos de los que se recabaron métricas cognitivas.
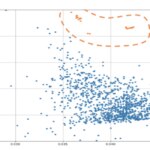
Comparativa de modelos por precisión contra exhaustividad de la 3ª generación (en naranja) contra la 2ª